


Managing Dependencies Between Data Pipelines
Presenting different techniques for managing dependencies between upstream and downstream data pipelines.

It’s a common challenge to manage dependency between data pipelines on data-driven systems such as analytical platforms which having data pipelines on different data layers or zones (ex ingestion, enrichment, aggregate), with each layer being dependent on successful completion of upstream layer data pipelines.
While real-time streaming pipelines have gained popularity in recent years, there are still many use-cases where companies rely on batch-oriented data processing for their applications specially analytical systems.
In a typical data warehouse or data lake architecture using ELT (Extract, Load, Transform) or ELETL pattern as referred by some architectures, the first set of data pipelines (Extract part) are usually responsible for collection and ingestion of data from source systems into the central data lake’s landing or raw zone/database. The ingestion pipelines are scheduled using a suitable event or time based internals. Downstream data pipelines would then use the data produced by these upstream pipelines to enrich, transform and aggregate data for different applications and analytical use-cases.
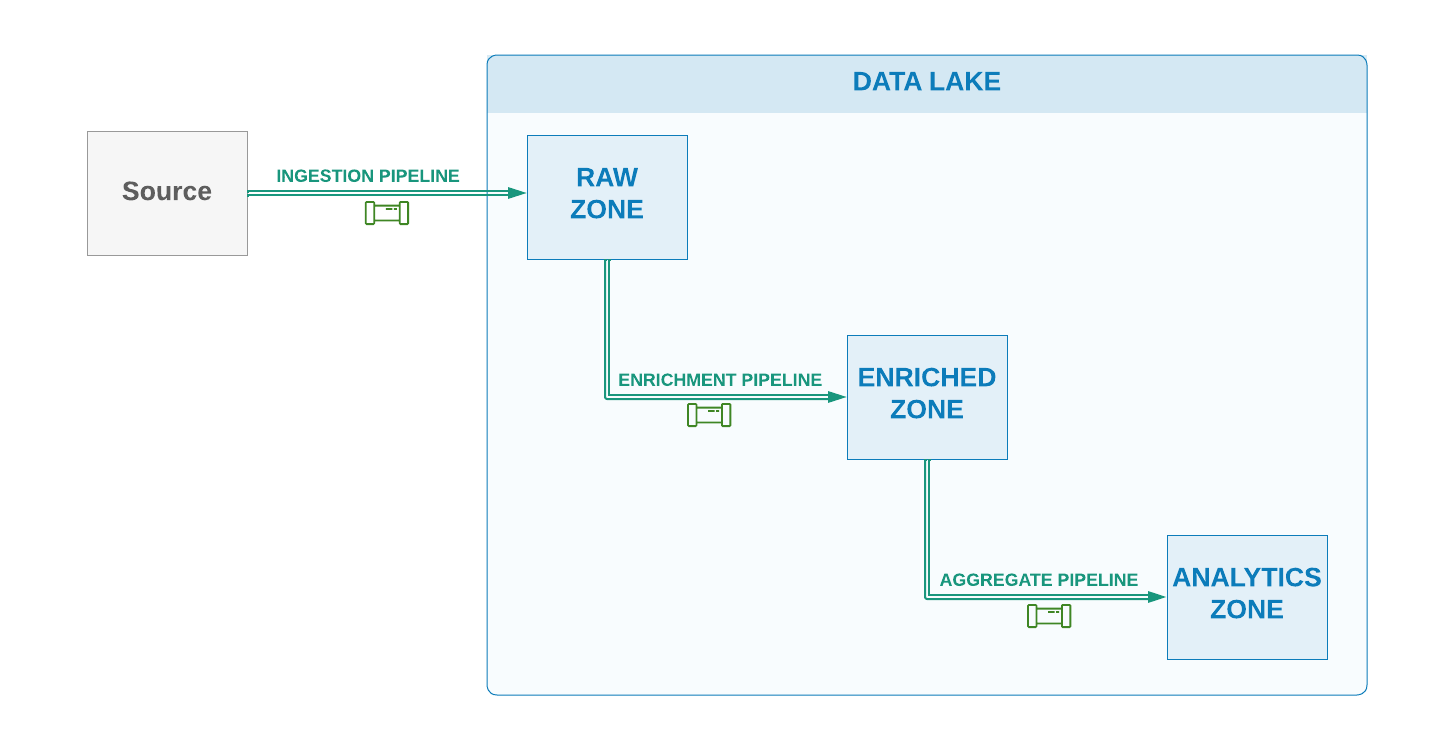
However an important design factor is how to best manage the dependencies between these set of pipelines being dependent on each other’s operations.
What follows are presentation of some techniques to manage such a dependency, starting from a fully decoupled solution, with coupling between data pipelines increased in each subsequent solution presented.
Technique #1 - Rely only on time notion
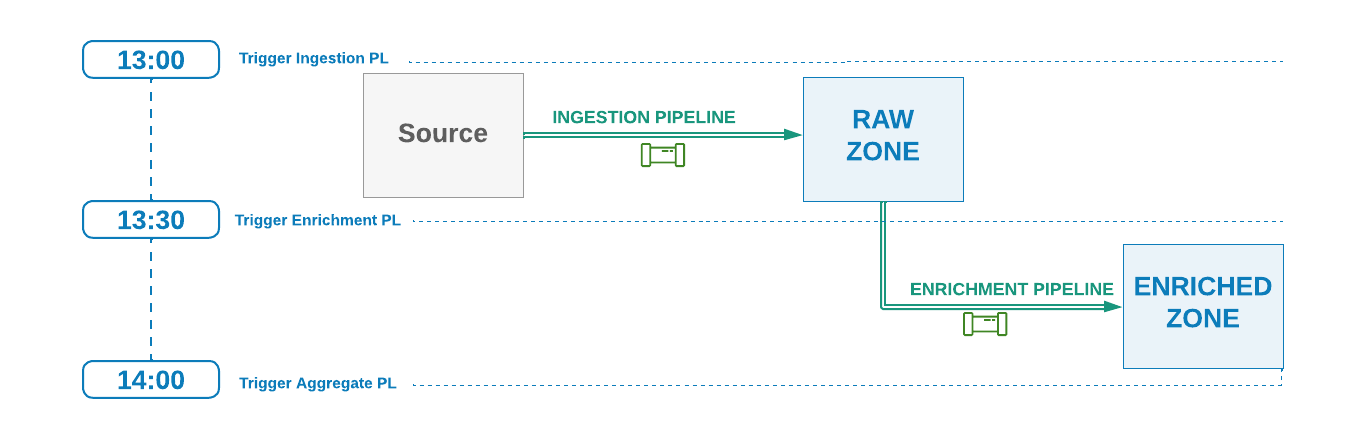
Using this technique each pipeline will execute based on a time schedule without managing any other dependencies in respect to other data pipelines.
If the upstream pipeline runs on hourly schedule, say at 13:00, and it is estimated that it takes about 20 minutes to complete, then the downstream pipeline can be scheduled to run at half-past each hour interval (ex 13:30).
Pros
No coupling or dependency management between downstream or upstream pipelines is required.
Each pipeline only relies on system clock time to run.
Different pipelines don’t need to have any knowledge or awareness about other downstream or upstream layers (self-managed).
Different pipelines can have different execution time windows without any impact on other workflows.
Different teams or developers can work on different data layers and their own set of data pipelines independently.
Cons
Since data pipelines are completely decoupled, if an upstream pipeline run fails or is delayed, the downstream pipeline will still execute with potentially incomplete or no data. Therefore the current job has to be retried when upstream pipeline has successfully retried or when the issue has been resolved.
Retry and reprocessing of upstream pipeline jobs are not automatically coordinated with the downstream pipelines and requires either manual intervention.
Technique #2 - Rely on time notion and upstream pipeline signal
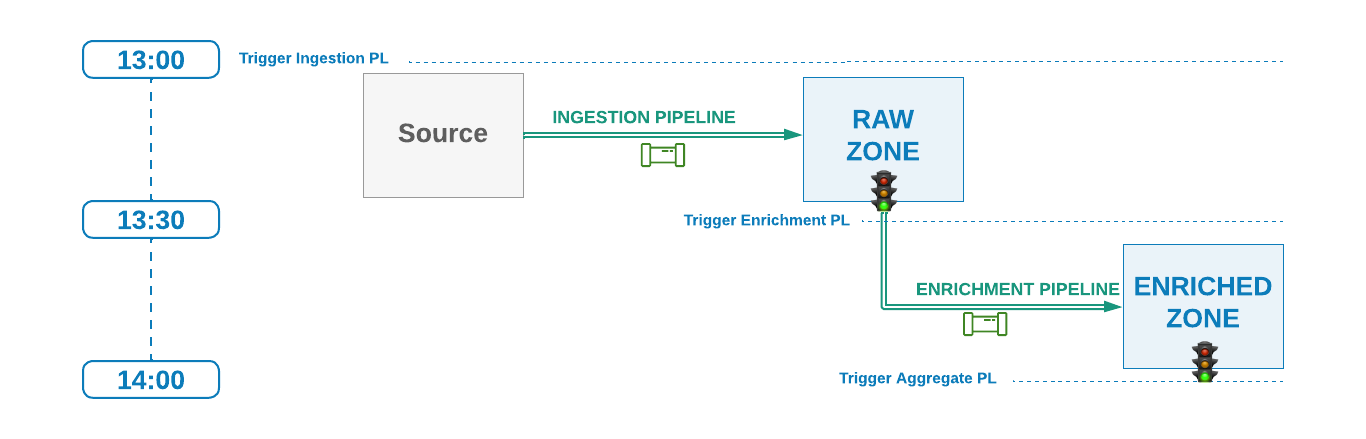
In this technique the downstream pipelines will still be scheduled using Technique #1 but only execute when the upstream pipeline has signaled it has successfully completed its current run.
In other words, the downstream pipelines wait for some sort of a signal from the upstream layer to start their next scheduled run. Possible mechanisms for creating a go-ahead signal include invisible empty file (ex .success) generation in current processed data partition, insertion of a record in a metadata table, or a notification pushed to an event bus.
This technique essentially builds a delay logic for the downstream scheduled pipelines to potentially delay their start of execution until success signal is produced by the upstream jobs.
Pros
Minimal coupling and dependency between different pipelines. The only dependency is the agreed signalling mechanism such as generating a hidden empty file inside the data partition.
The downstream pipelines will only execute when the upstream pipeline has finished successfully. This saves computational resources and cost if operating on cloud.
If there is a delay in upstream pipelines, the downstream pipelines will wait before execution which avoids running on incomplete or no data which would require rerunning the job again, and therefore reducing dataops overhead.
Different pipelines can have different execution time windows without any series impact on other workflows.
Different teams or developers can work on different data layers and their own set of data pipelines independently once the agreement on signalling mechanism is established.
Cons
Retry and reprocessing of upstream pipeline runs which had completed successfully once before, are not automatically coordinated with the downstream pipelines since the downstream pipelines are already executed after receiving green signal. Therefore manual communication and intervention, or creation of automatic triggers on an event of re-running the pipeline is required.
Technique #3 - Rely on time notion and upstream pipeline completion
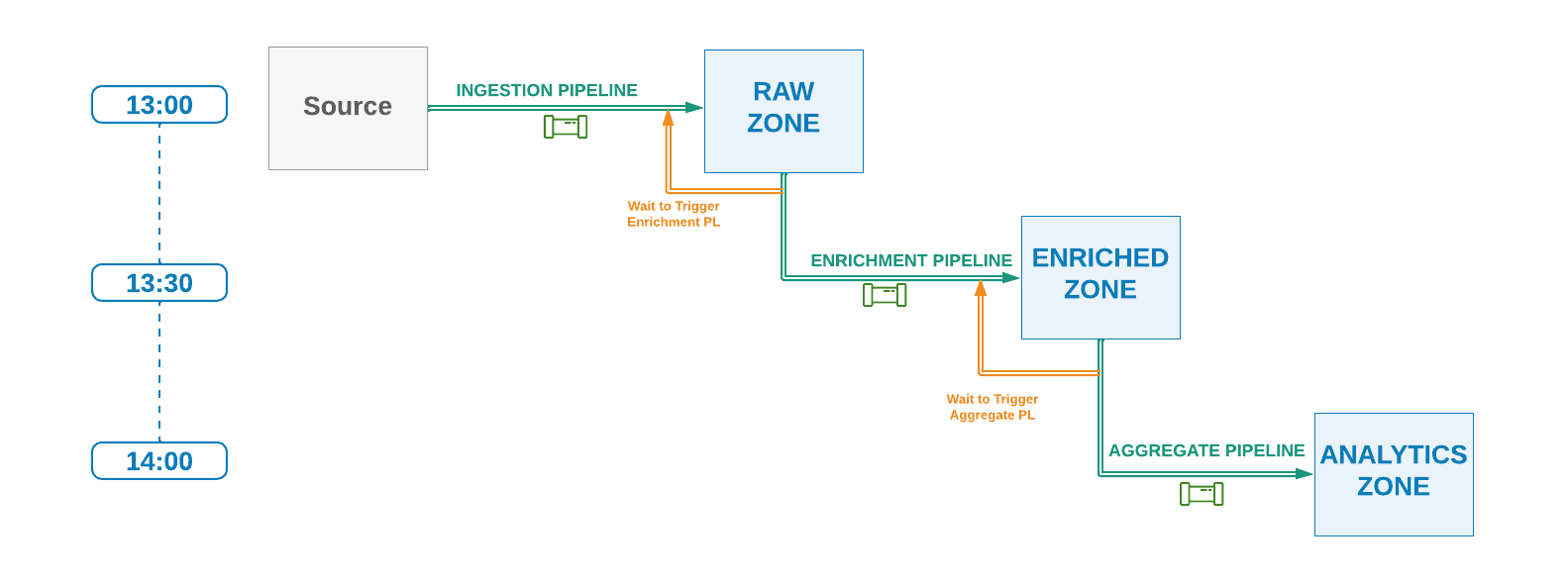
This technique is similar to the previous technique with the difference that instead of using a decoupled signalling mechanism to coordinate the flow of work, the downstream pipelines a loosely coupled with upstream pipelines, and will wait for the completion of upstream pipeline before starting their current run. This would require that the data pipelines are managed and orchestrated on the same workflow management system.
As an example Apache Airflow orchestration engine provides a task called ExternalTaskSensor which can detect and signal when a task from a different pipeline in a DAG has been completed.
Pros
The downstream pipeline will only execute when the upstream pipeline has finished successfully. This saves cluster resources and cost.
If there is a delay in upstream pipeline, the downstream pipeline will not be executed which avoids running on corrupted, incomplete or no data which would require rerunning the job again.
No signalling logic is required to be implemented if not available already in Technique #2.
Cons
There different layers are more coupled and the dependency is increased between the different pipelines.
The downstream pipeline has to know what to call, how to call it's upstream dependent pipelines.
Changes to the upstream pipelines such as changing the pipeline or task name might affect downstream pipeline as it has to updated accordingly.
Using this technique works best when the pipelines are running on the same time interval. For instance if the parent pipeline is running on hourly basis, then the downstream pipeline should ideally also be running hourly too. Otherwise if for instance the downstream pipeline is rather running on two-hourly basis then coordinating the dependency between the two pipeline could become complicated.
Technique #4 - Sequentially Orchestrated Pipelines
This technique is similar to the previous technique; however, the pipelines are triggered sequentially with each upstream pipeline calling or triggering its immediate downstream pipelines after it has completed successfully, rather than the downstream pipeline waiting for upstream one.
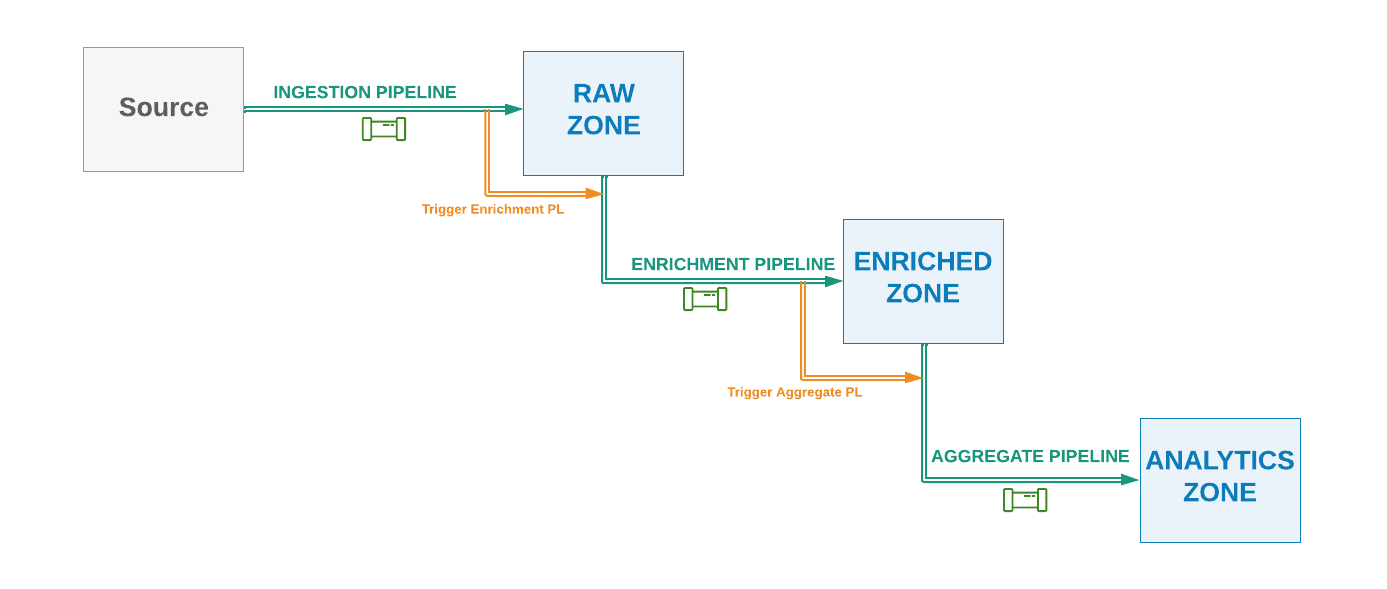
Pros
The downstream pipeline only executes when the upstream pipeline has finished successfully. This saves cluster resources and cost.
If there is a delay in upstream pipeline, the downstream pipeline will not be executed which avoids running on incomplete or no data which would require rerunning the job again.
Usually only suitable if the end-to-end data workflow orchestration is managed by a one team.
Cons
There different layers are more tightly coupled and the dependency is increased between the pipelines.
The upstream pipeline has to have knowledge about its immediate downstream pipelines, what to call and how to call its downstream dependent pipelines.
Unlike previous technique, for newly added downstream consumers, the upstream pipeline has to be modified to trigger the new pipeline after its completion.
Changes to the downstream pipelines, such as changing the pipeline name might affect upstream pipeline as it has to updated accordingly.
Feedback loops might be required to determine whether the downstream jobs have started or not.
Similar to previous technique, using this technique would probably require the downstream pipelines to be running on the same time interval. For instance if the parent pipeline is running on hourly basis, then the downstream pipeline should ideally also be running hourly.
Due to increased coupling between data pipelines on different layer, working independently on each data layer might become a challenge.
This pattern can get more complicated when multiple downstream layers and integration pipelines are added. When managing multiple downstream pipelines, they either have to be coordinated sequentially where each pipeline only triggers its immediate downstream pipelines, or as shown in the following figure, they are all managed and triggered by the top parent pipeline, which in this case it would require a feedback loop to know when a pipeline is completed before executing its further dependent pipelines.
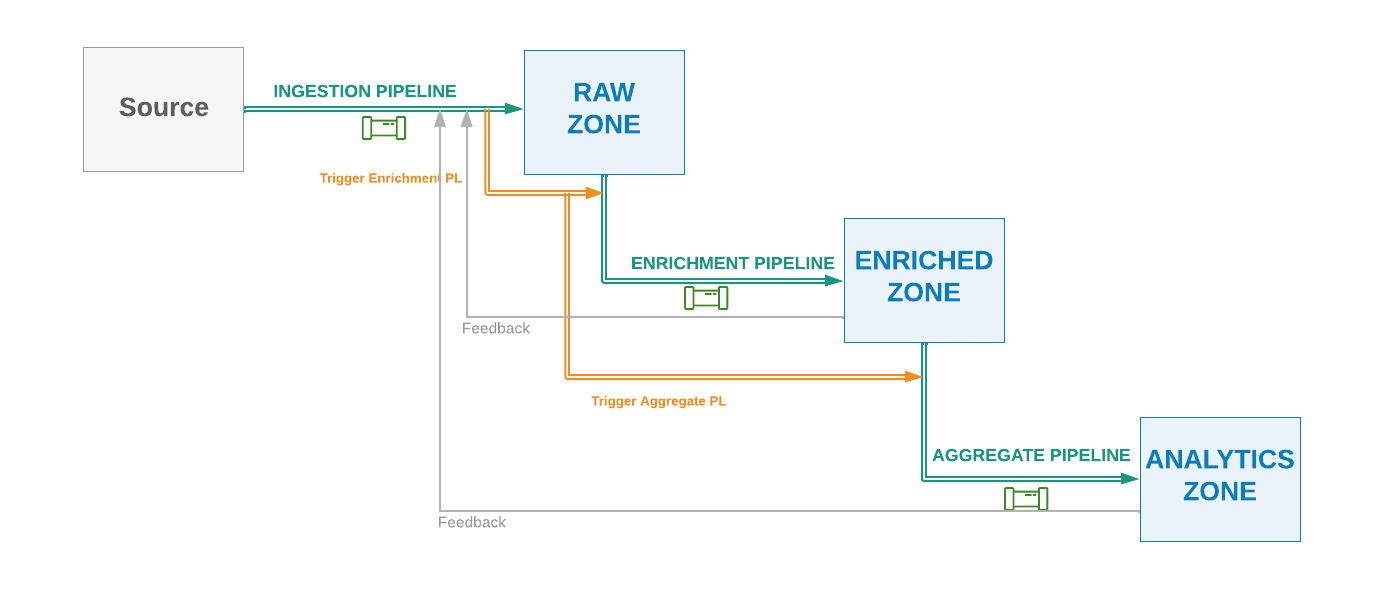
It has to be emphasized that for the workflows to be deterministic it means the entire workflow, and the dependent data pipelines must produce the same result every time it runs or is re-executed using the same input.
Conclusion
There might be other techniques used by data engineers to manage dependencies between separate batch data pipelines. In this article I presented some common techniques which I have used and seen in production. There are tradeoffs in terms of coupling, operational complexity and workflow management when deciding how to manage pipelines dependency, and depending on the use-case and the environment one should choose the most suitable approach.