


The Evolution of Business Intelligence: From Monolithic to Composable Architecture
Data Landscape Trends: 2024-2025 Series

As we dive into 2025, the data engineering field continues its dramatic evolution. In this series, we'll explore the transformative trends reshaping the data engineering landscape, from emerging architectural patterns to new tooling approaches.
This is part one of our series, focusing on the evolution of Business Intelligence architecture.
Introduction
The Business Intelligence (BI) landscape has undergone significant transformation in recent years, particularly in how data is presented and processed.
This evolution reflects a broader shift from monolithic architectures to more flexible, composable solutions that better serve modern analytics needs.
This article traces the evolution of BI architecture through several key phases: from traditional monolithic systems, through the emergence of headless and bottomless BI, to the latest developments in BI-as-Code and embedded analytics.
Traditional BI Architecture: The Monolithic Approach
Traditional BI tools were built as comprehensive, tightly-coupled systems with a significant focus on user interface design.
These systems provided extensive flexibility through click-through functionality for slicing, dicing, and grouping data using various visualisations. At their core, these systems were composed of three interconnected components that worked in harmony to deliver business insights.
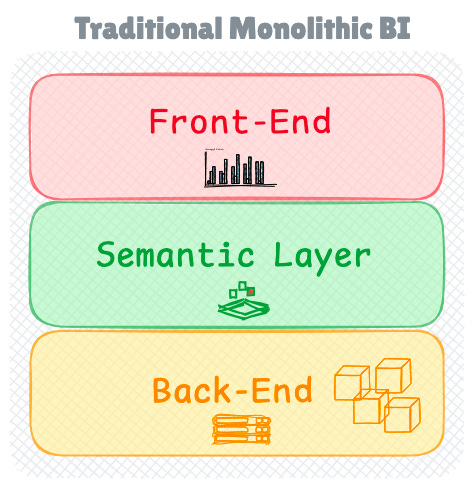
The backend layer served as the foundation, handling data ingestion from OLAP sources and building optimised data cubes on the server. These cubes contained pre-computed dimensions that enabled real-time data exploration.
Working in concert with the backend, the frontend layer provided the visualisation interface, connecting to the backend to access data cubes and construct dashboards.
The semantic layer completed the architecture by defining key performance indicators (KPIs) and metrics embedded within the BI software.
The Drawbacks of Traditional BI Tools
While powerful, these traditional systems came with significant overhead.
Organisations needed substantial infrastructure for on-premise deployment before managed Cloud BI services become more accessible, and the licensing costs were often prohibitive.
Implementation timelines stretched long, with even proof-of-concept demonstrations requiring weeks of setup and configuration. For businesses serving large user bases, the resource requirements were particularly demanding.
These fundamental limitations, combined with the growing need for flexibility and cost-effectiveness, sparked a series of architectural innovations in the BI landscape.
The Rise of Bottomless BI Tools
In response to these challenges, a new generation of lightweight, disaggregated BI tools emerged. Notable open-source solutions like Apache Superset, Metabase, and Redash began appearing about a decade ago, with Superset, originally developed at Airbnb, gaining particular prominence in the ecosystem.
These new tools adopted a "bottomless" architecture, eliminating the heavy backend server traditionally used for computation and building and caching cube objects.
Instead of maintaining their own computation layer, they rely on connected source engines for querying and providing data to dashboards at runtime. This architectural shift introduces different strategies for data serving.
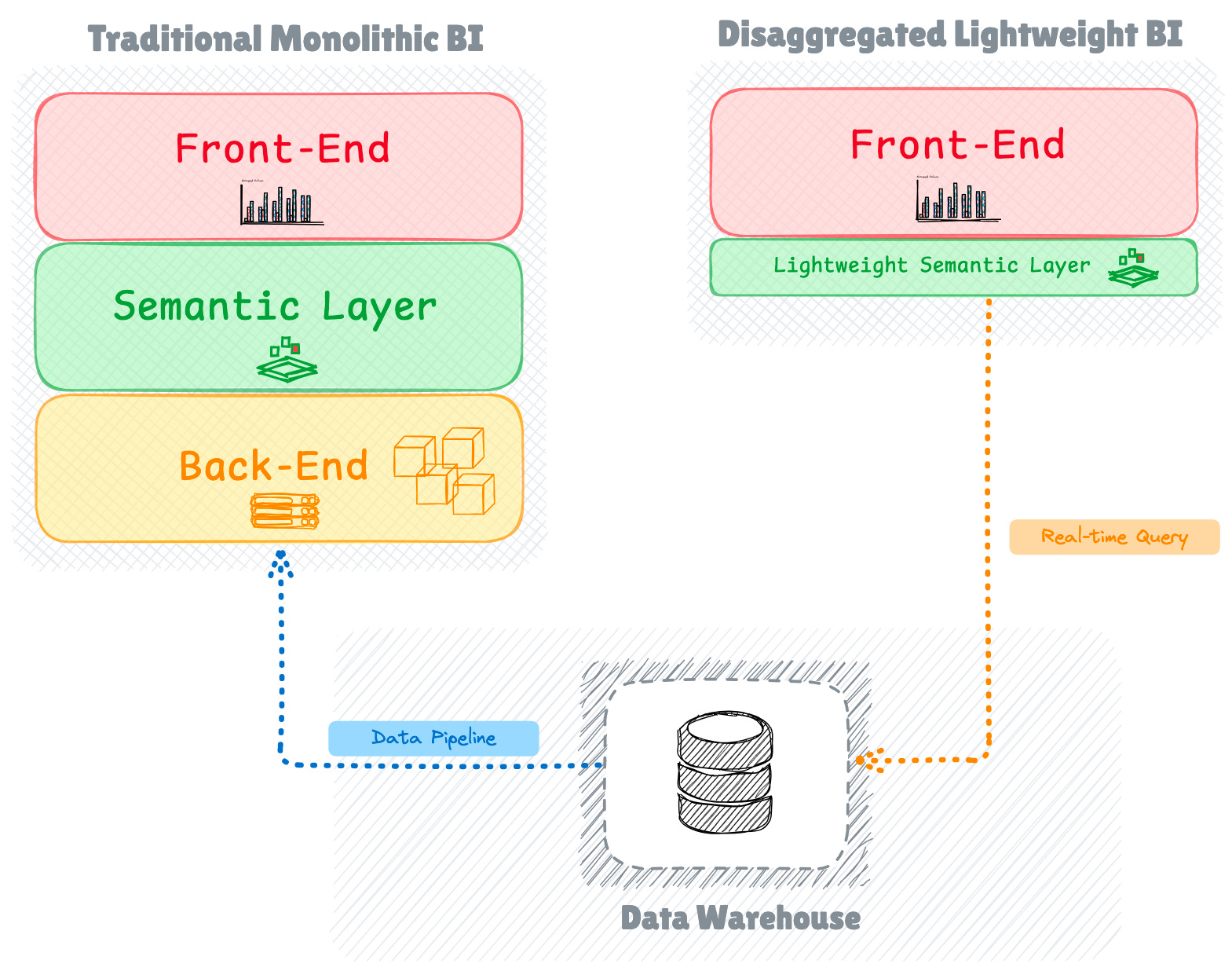
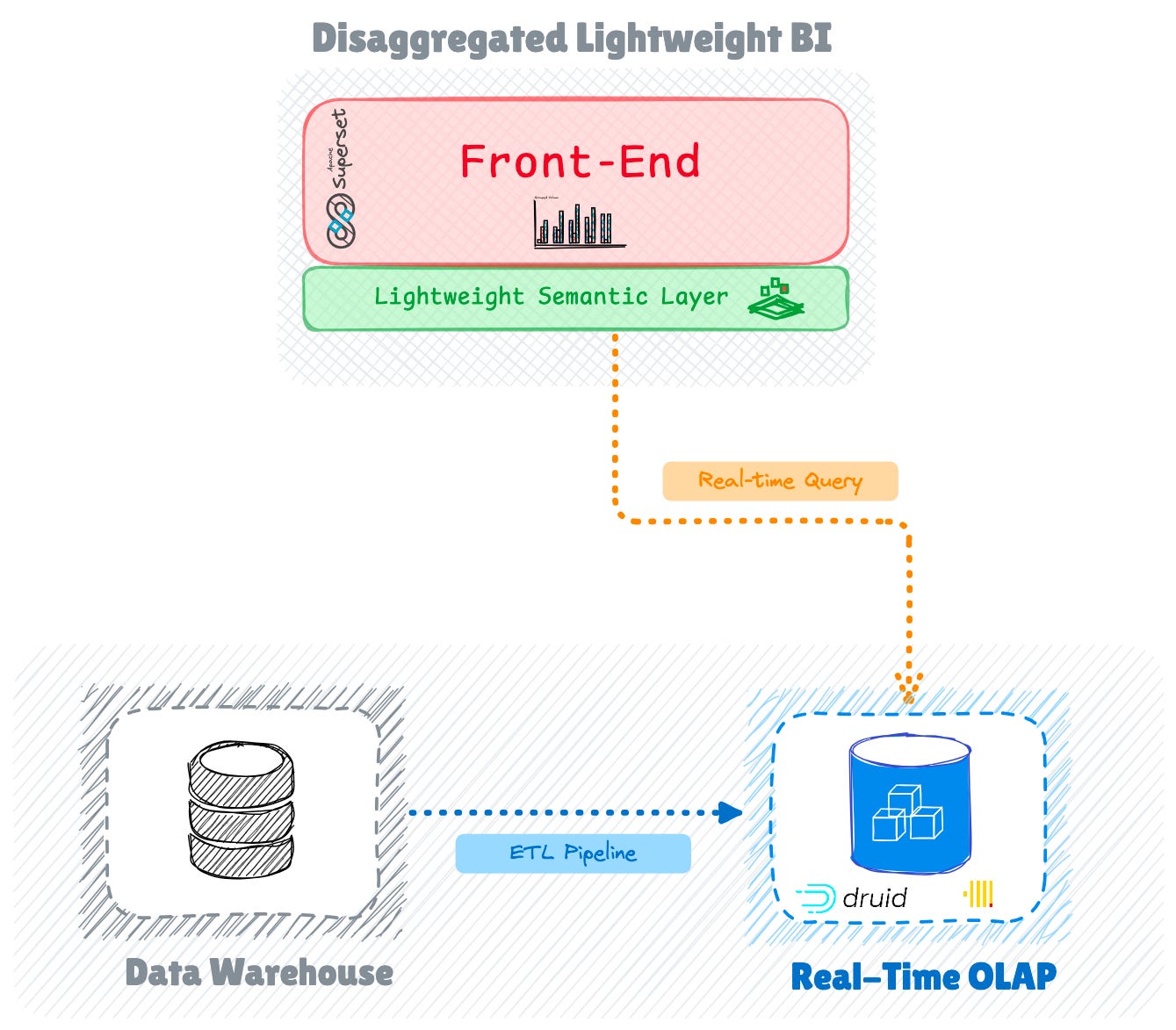
Dealing With Query Latency
The elimination of the backend report server presents bottomless BI tools with a significant challenge: managing query latency when accessing data in real-time.
To address this challenge, these tools employ several optimisation strategies. One key approach involves utilising pre-computed aggregates stored in the primary data warehouse, allowing dashboards to serve results efficiently.
Additionally, tools like Superset implement caching layers using Redis to store frequently accessed datasets. This caching mechanism proves particularly effective: once an initial query loads a dataset, subsequent visualisations and dashboard reloads can access the cached version until the underlying data changes, significantly reducing response times.
For companies handling larger data volumes, integration with specialised real-time OLAP engines like Druid and ClickHouse provides low-latency analytics capabilities.
The Emergence of Universal Semantic Layer
As the industry sought more flexibility in their BI stack, portable semantic layer or what is known as headless BI emerged as an intermediate step between traditional monolithic systems and fully lightweight solutions.
Headless BI platforms provide a dedicated semantic layer and some combine query engine while allowing organisations to use any frontend visualisation tool of their choice. This approach fully disaggregates the presentation layer (front-end) from the semantic layer.
With tools like Cube and MetricFlow (now part of dbt Labs), for example, organisations can define their metrics and data models in a central location, then connect various visualisation tools, custom applications, or lightweight BI solutions to this semantic layer.
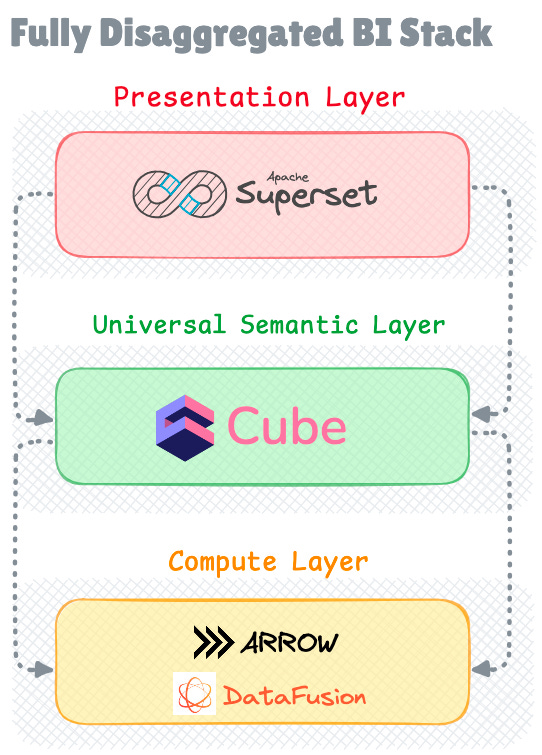
This architectural pattern offers several advantages over traditional BI systems. It enables organisations to maintain consistent metric definitions across different visualisation tools, supports multiple frontend applications simultaneously, and provides better integration capabilities with modern data stacks.
The semantic layer acts as a universal translator between data sources and visualisation layers, ensuring consistent business logic across all analytics applications.
The BI-as-Code Movement
Recent years have witnessed the emergence of BI-as-Code, representing an even lighter approach to dashboard and interactive data app development.
This paradigm shift brings software engineering workflows to BI development, enabling version control, testing, and continuous integration practices. Since code serves as the primary abstraction rather than a user interface, developers can implement proper development workflows before deploying to production.
Prominent tools in this space, such as Streamlit, integrate seamlessly with the Python ecosystem, allowing developers to remain within their Python projects without requiring external software installation for building dashboards and data applications.
The approach emphasises simplicity and speed, using SQL and declarative tools like YAML for dashboard creation. The resulting web apps can be easily self-hosted, providing deployment flexibility.
While Streamlit leads the pack in popularity, open source newcomers like Evidence, Rill, Vizro, and Quary have emerged in recent years, each bringing their own approach to the BI-as-Code concept.
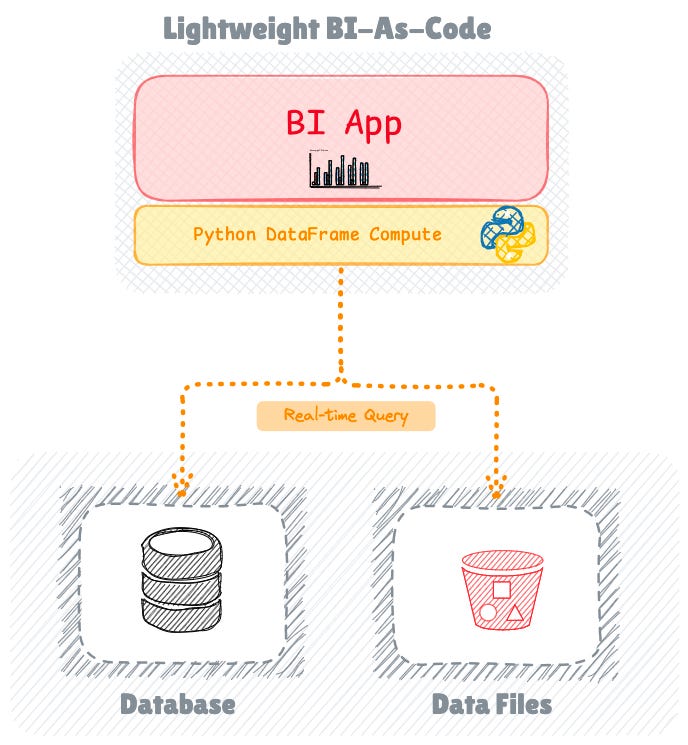
BI-as-Code Limitations
BI-as-Code tools currently have limitations in terms of interactive data exploration features and providing enterprise-grade BI capabilities.
They don't provide the same user experience for slicing and dicing data as traditional BI tools, and they lack data governance and semantic layer support found in both traditional and lightweight BI solutions.
Nevertheless, BI-as-Code are increasingly being adopted in various ways such as data science teams creating interactive standalone apps, product teams building embedded analytics features and analysts developing internal data applications.
The New Emerging Trend: BI + Embedded Analytics
The latest evolution in BI architecture involves integrating high-performance, embeddable OLAP query engines like Apache DataFusion and DuckDB.
This approach bridges several gaps in the current landscape while maintaining the benefits of lightweight, disaggregated architectures.
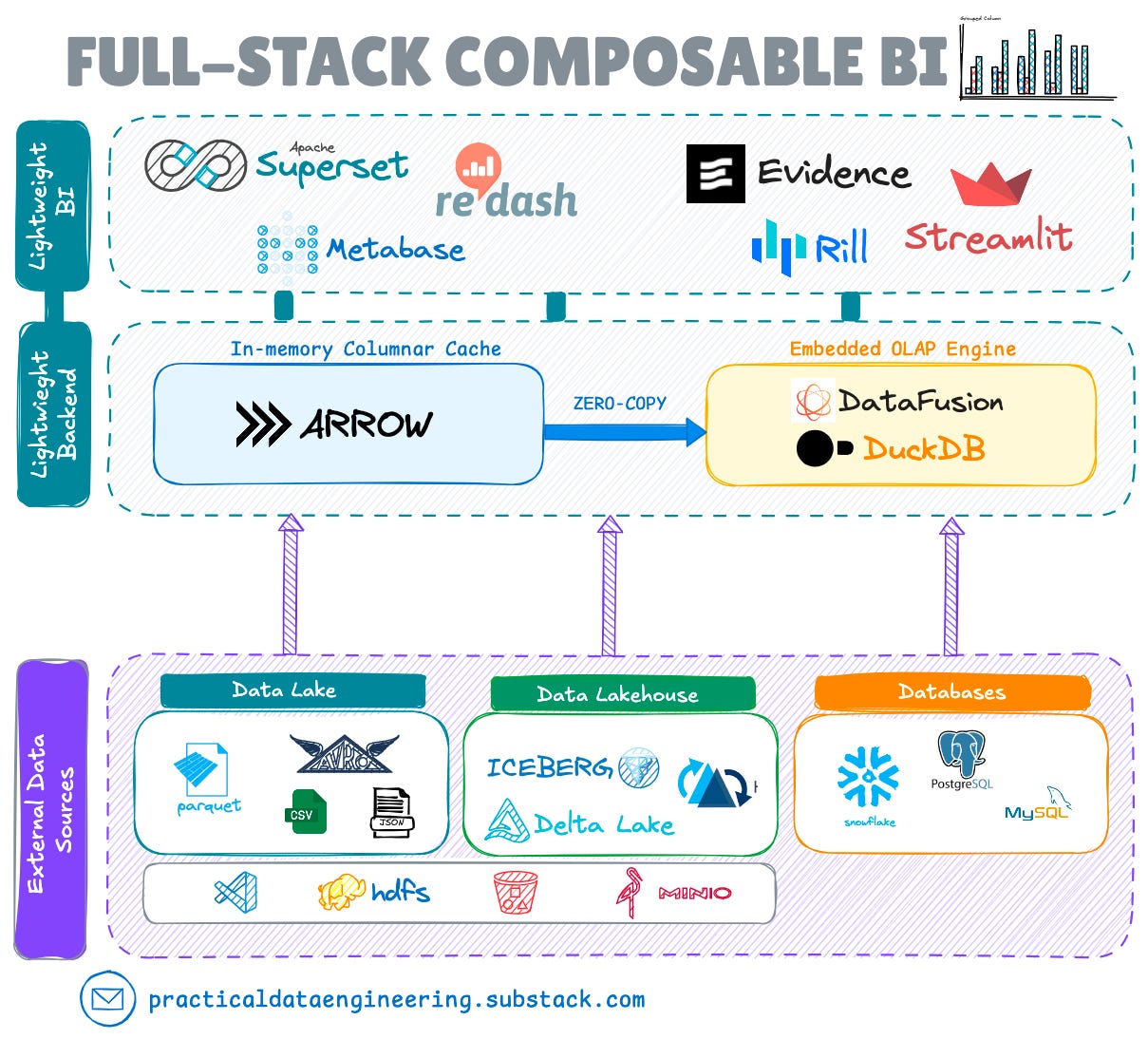
The new full-stack composable BI architecture brings several key advantages:
First, it offers true composability and interoperability, with ability to swap embedded compute engines as needed while maintaining a standalone semantic layer for metric definitions.
The embedded analytics capabilities are particularly powerful, with zero-copy integration through standard frameworks mainly Apache Arrow enabling microsecond-level data access through optimised in-memory columnar formats.
Zero-copy integration refers to a performance optimisation technique where data can be accessed and processed without needing to serialise and convert data between different in-memory representations. In the context of DataFusion and Apache Arrow, this means that when data is loaded into memory in Arrow's columnar format, DataFusion can directly perform computations on this data without needing to convert or copy it into its own internal format.
The direct support for data lakes and lakehouses represents another significant advance, allowing teams to build dashboards directly on top of open table formats like Apache Iceberg and Apache Hudi without intermediate data movement.
This capability, combined with comprehensive federated query support, resolves a long-standing challenge in exisitng lightweight BI tools that struggled to effectively combine data from multiple sources without requiring to use an external federated query engine.
Industry Adoption
Industry adoption of embedded query engines is gaining significant momentum across the BI ecosystem. Commercial vendors are leading this transformation: Omni has integrated DuckDB as its core analytics engine, while Cube.dev has implemented a sophisticated combination of Apache Arrow and DataFusion in its headless BI architecture.
Similarly, GoodData has embraced this trend by implementing Apache Arrow as the foundation of its FlexQuery system's caching layer, and Preset (Managed Superset) has integrated with MotherDuck (Managed DuckDB ).
In the open-source space, both Superset (using duckdb-engine library ) and Metabase now support embedded DuckDB connection, with potential future integration into their core engines.
The BI-as-Code movement has also embraced embedded engines. Rilldata announced DuckDB integration in 2023 for auto-profiling and interactive modeling in dashboard development, while Evidence introduced Universal SQL in 2024, powered by DuckDB's WebAssembly implementation.
Conclusion
The Business Intelligence landscape continues its evolution toward more flexible, efficient solutions.
Each architectural evolution has brought distinct advantages: headless BI enabled consistent metrics across tools, bottomless BI reduced infrastructure complexity, BI-as-Code brought developer workflows to analytics, and embedded engines are now combining these benefits with high-performance query capabilities.
The integration of embedded query engines with lightweight BI tools represents a promising direction for implementation of lightweight BI, combining the best aspects of traditional BI capabilities with modern architectural patterns. As these technologies mature and the ecosystem grows, companies can look forward to increasingly sophisticated yet composable solutions for their data analysis needs.