


The History and Evolution of Open Table Formats - Part I
From Hive to High Performance: A Journey Through the Evolution of Data Management on Data Lakes

If you have been following trends in data engineering landscape over the past few years surely you have been hearing a lot about Open Table Formats and Data Lakehouse, if not already working with them! But what is all the hype about table formats if they have always existed and we have always been working with tables when dealing with structured data in any application?
In this blog post, we will delve into the history and evolution of open table formats within the data landscape. We will explore the challenges that led to their inception, the key innovations that have defined them, and the impact they have had on the industry.
By understanding the journey from traditional database management systems to the modern open table formats, we can better appreciate the current state of data technology and anticipate future trends.
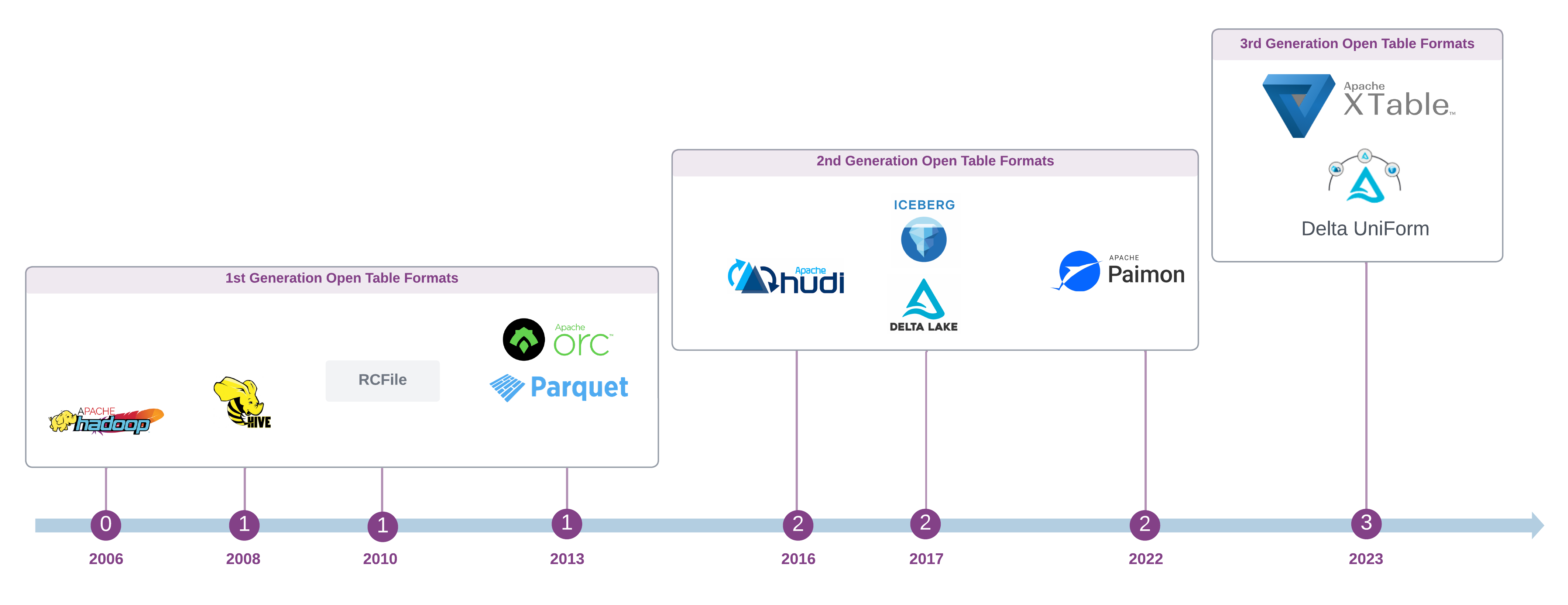
In Part I, we will discuss the origin and history of storing and managing data in tabular format, and the emergence of first generation open table format.
In Part II, Second and third generation open table formats will be discussed.
The origin of Table Formats
Presenting information in a two-dimensional tabular format has been the most fundamental and universal method for displaying structured data, with roots tracing back over 3500 years to the old Babylonian period when the most ancient table data were recorded on clay tablets.
The modern concept of database tables emerged with the invention of relational databases, inspired by E.F. Codd's paper on the Relational Model published in 1970.
Since then, table formats have been the primary abstraction for managing and working with structured data in relational database management systems, such as the pioneering System R. Thus, the concept of table formats in storage systems is not novel, having been a staple for the past half-century.
Table Format Abstraction
Data tables are logical datasets, an abstraction layer over physical data files stored on disk, providing a unified, two-dimensional tabular view of records. The storage engine combines records from various objects for a dataset and presents them as one or more logical tables to the end user.
This logical table presentation offers the advantage of decoupling and hiding the physical characteristics of data from applications and users, allowing for the evolution, optimisation, and modification of physical implementation details without impacting users.
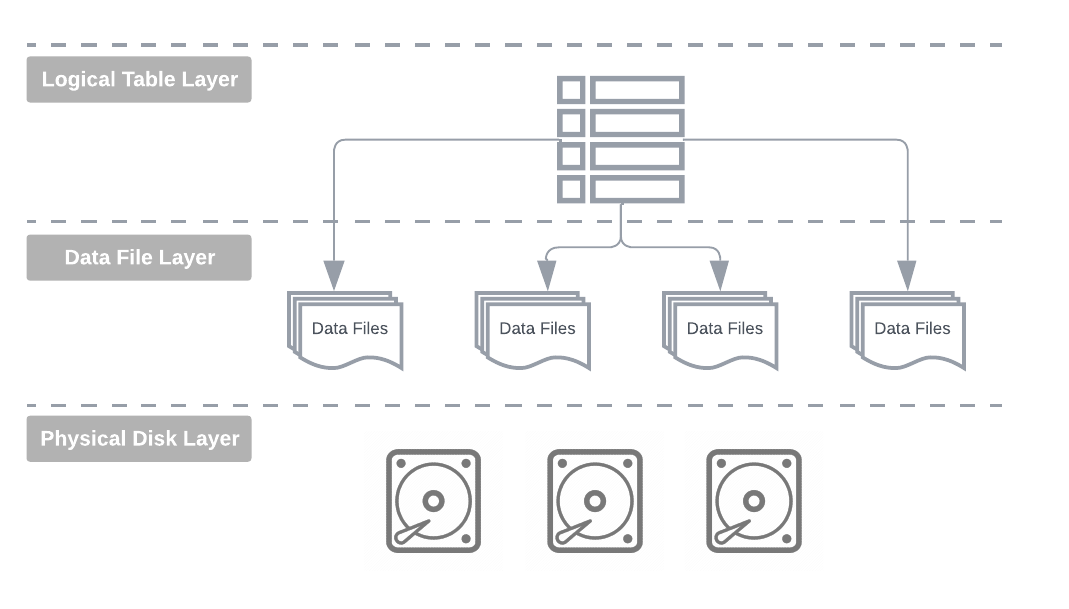
So, we've been hearing a ton about open table formats lately, but what's the big deal? And what's the difference between open and non-open or closed formats anyway? To figure that out, let's dive into how a general database management system is implemented.
Relational Table Format
Prior to the Big Data era and emerge of Apache Hadoop in mid 2000s, traditional Database Management Systems (DBMS) adhered to a monolithic architectural design.
This architecture is comprised of several highly interconnected and tightly coupled layers, each dedicated to specific functionalities essential for the database's operation but all the components are combined to form a single unified system. The storage layer, in particular, managed the physical aspects of data persistence.
At the core of this structure lays the Storage Engine. This component served as the lowest abstraction level, overseeing the physical organisation and management of data on disk. Critical tasks such as transaction management, concurrency control, index management, and recovery were also handled by the storage engine.
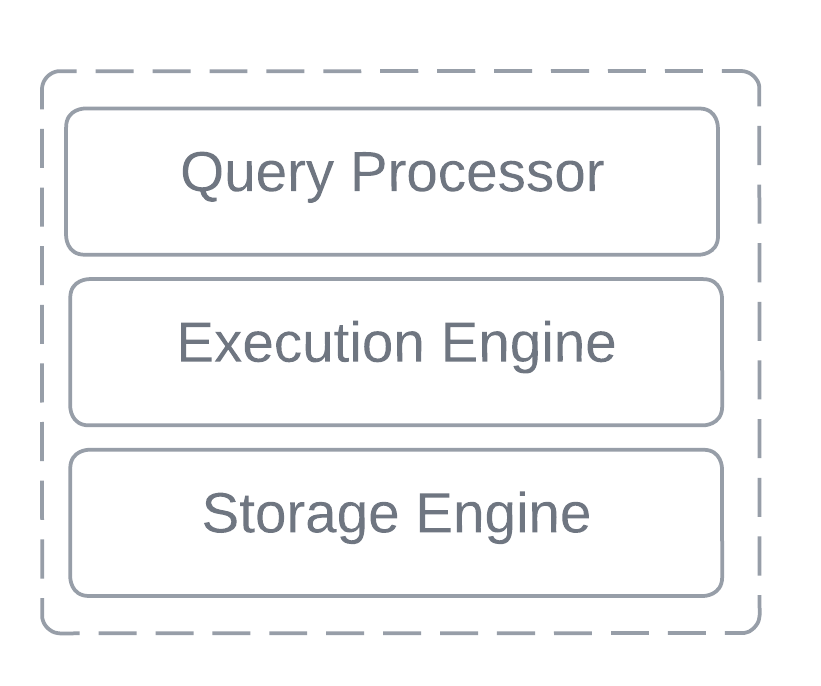
Crucially, the query and presentation layers operated in isolation from the intricacies of the storage layer. Data traversed these layers during read and write operations, with each layer imposing its own abstraction. This encapsulation meant that the physical layout and storage format of data remained concealed from external systems.
What’s the implication?
What that means is that, it was not possible to directly access or manipulate database's physical data files using other systems or programming languages like Python as we do now a days.
Moreover, it lacked interoperability as it one cannot just copy database files to another system or simply pointing a generic query engine at a the database's files on OS and interact with the data.
Given these constraints, the concept of an Open Table Format (OTF) as we understand it today was non-existent. Traditional databases employed proprietary storage formats tightly integrated with their specific implementations.
Are we saying there is a fundamental flaw in traditional DBMS architecture!?
Many would argue that this is actually not a bad design at all. After all, normal users shouldn't care, know or even change how the underlying physical layer is implemented because they can do catastrophic things! additionally, considerable technical expertise is applied to integrate interconnected components into a cohesive complex system.
Considering software design best practices it’s a valid argument as the design fully encapsulates the complexities of managing it, however the tradeoff is that this closed and tightly coupled design hinders interoperability, portability and open collaboration to build scalable and innovative systems based on open standards.
But is it possible to have the best of both worlds? That is, having highly interoperable, portable, open and scalable data systems and still be able to encapsulate the complexities of managing the low-level tasks such as managing data files on disk? We will find out later in the article.
Hadoop and Big Data Revolution
Let's fast forward from the 1970s to 2006, when the BIG DATA Revolution took place and the data landscape underwent a seismic shift when Apache Hadoop project was born out of Yahoo leading to disassembly of database systems.
I will not discuss the internals of Apache Hadoop and its architecture as there are lots of material available if you are unfamiliar with it. But one major architectural breakthrough was the decoupling of storage and compute.
This fundamental architectural change allowed for the storage of vast amounts of data in common semi-structured text-based formats such as CSV and JSON, or binary formats like Avro, Parquet, and ORC, on HDFS distributed files system deployed on affordable commodity hardware.
Data could be stored much like files on a local file system and processed using distributed processing frameworks of choice like MapReduce, Pig, Hive, Impala and Presto.
For the first time, businesses could store vast amounts of data in their preferred open formats, and leverage different compute engines for various workloads, enabling large-scale analytics. This was a game-changer for those accustomed to inflexible, expensive, monolithic storage systems and proprietary data warehouses.
But the real breakthrough, as stated by AMPLab co-director Michael Franklin was achieving data independence as result of the new decoupled architecture:
The real breakthrough was the separation of the logical view you have of the data and how you want to work with it, from the physical reality of how the data is actually stored.
That is why Big Data was such a Big Hype at the time generating such excitement with enterprises rushing to bring the elephant in the room – a similar level of hype surrounds Generative AI today, creating a sense of déjà vu for some. Nevertheless, the big data was a true revolution, breaking free from the confines of traditional systems and providing the foundation of many innovations that followed next in the open data ecosystem.
1st Generation OTF - The Birth of Open Table Format
The initial release of Apache Hadoop presented significant challenges for data engineers.
Expressing data analysis and processing workloads in MapReduce logic using Java was both complex and time-consuming. Moreover, Hadoop lacked a mechanism for storing and managing schemas for datasets on its file system.
While engineers appreciated Hadoop's flexibility, they yearned for the familiarity of SQL and the two-dimensional table format inherent to relational databases.
To bridge this gap, Facebook (now Meta), an early and influential Hadoop adopter, initiated the Hive project. The goal was to introduce SQL and tabular structures, familiar from traditional relational databases, into the Hadoop and HDFS ecosystem.
However a key distinction was its new architectural approach:
Being built on top of the decoupled physical layer, leveraging open data formats stored on HDFS distributed file system.
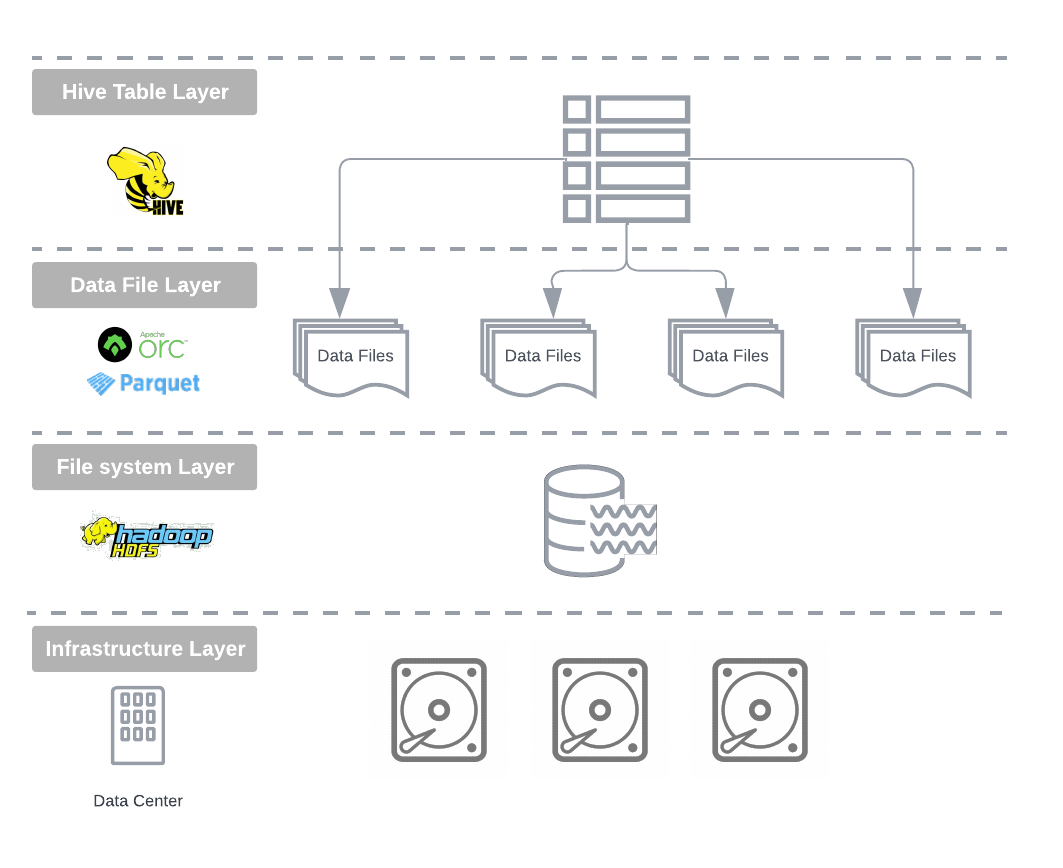
Impact of Apache Hive
Facebook open-sourced Hive in 2008, making it available to the broader community. A few years later, Cloudera, a prominent Hadoop vendor, developed Apache Impala.
Similar to Hive, Impala offered table management on HDFS, incorporating schema management and features like automatic file format conversion and compaction.
The introduction of Apache Hive and Impala into the Hadoop stack, the concept of open table formats built upon open file formats was born. Managed and external tables, along with directory-based partitioning, became the primary abstractions for data ingestion, data modeling, and management within the Hadoop ecosystem.
This new data architecture enabled data integration and processing pipelines to operate independently, loading data files into HDFS in the appropriate format without requiring knowledge on how and by which query engine the data would be consumed.
Evolution of Columnar Binary File Formats
Another pivotal advancement was the development of efficient columnar open file formats. This began with RCFiles, a first-generation columnar binary serialisation framework from Apache Hive project.
Subsequent innovations included Apache ORC as an improved version of RCFile, released in 2013, and Apache Parquet, a joint effort between Twitter and Cloudera, also released in 2013.
These new open file formats dramatically enhanced the performance of OLAP-based analytical workloads on Hadoop, laying the groundwork for building OLAP storage engines directly on data lakes.
Since then, ORC and Parquet have become the de facto standard open file format for managing data at rest on data lakes, with Parquet being more popular and enjoying wider adoption and support in the ecosystem.
Next we will dive deeper into how Hive table format is structured, but before that let's generalise the physical design the engines such as Hive and Impala use which heavily relies on the file system directory hierarchy. Lets call it directory-oriented table formats.
Directory-oriented Table Formats
The most fundamental approach to treating data as a table in a distributed file system such as HDFS (i.e., a data lake) involves projecting a table onto a directory containing immutable data files and potentially sub-directories for partitioning.
The core principle is to organise data files in a directory tree. In essence, a table is just a collection of files tracked at the directory level, accessible by various tools and compute engines.
The important factor to note is that this architecture is inherently tied to the physical file system layout, relying on file and directory operations for data management. This has been the standard practice for storing data in data lakes since the inception of Hadoop.
Directory-based partitioning allows for organising files based on attributes like event or process date. Schema information can be embedded within data files or managed externally by a schema registry.
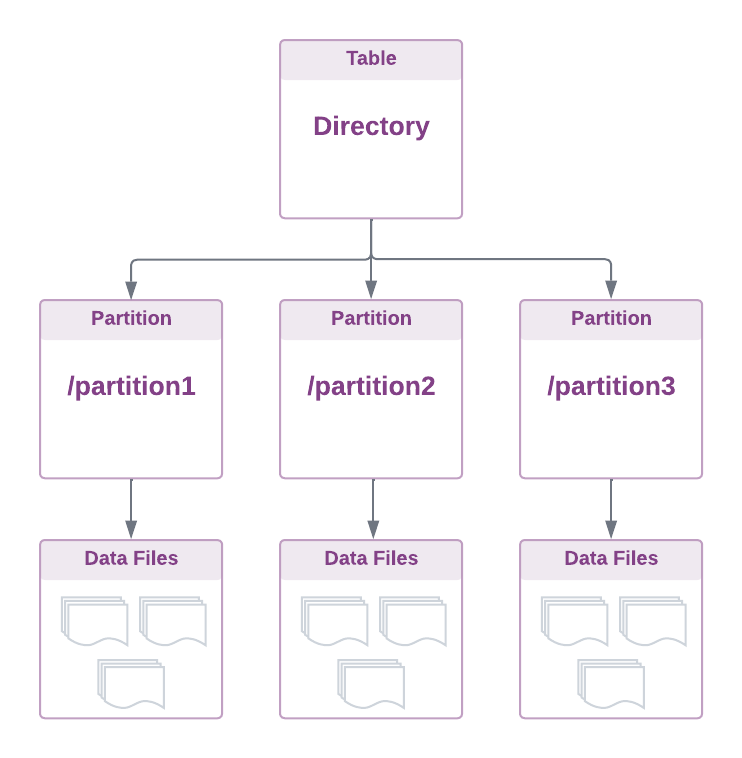
Since table partitions are represented as sub-directories, it becomes the responsibility of the query engines to parse and scan each partition represented as a sub-directory in order to identify the relevant data files during query planning phase.
This implies that the physical partitioning is tightly coupled with the logical partitioning on the table level with its own constraints which will be discussed later.
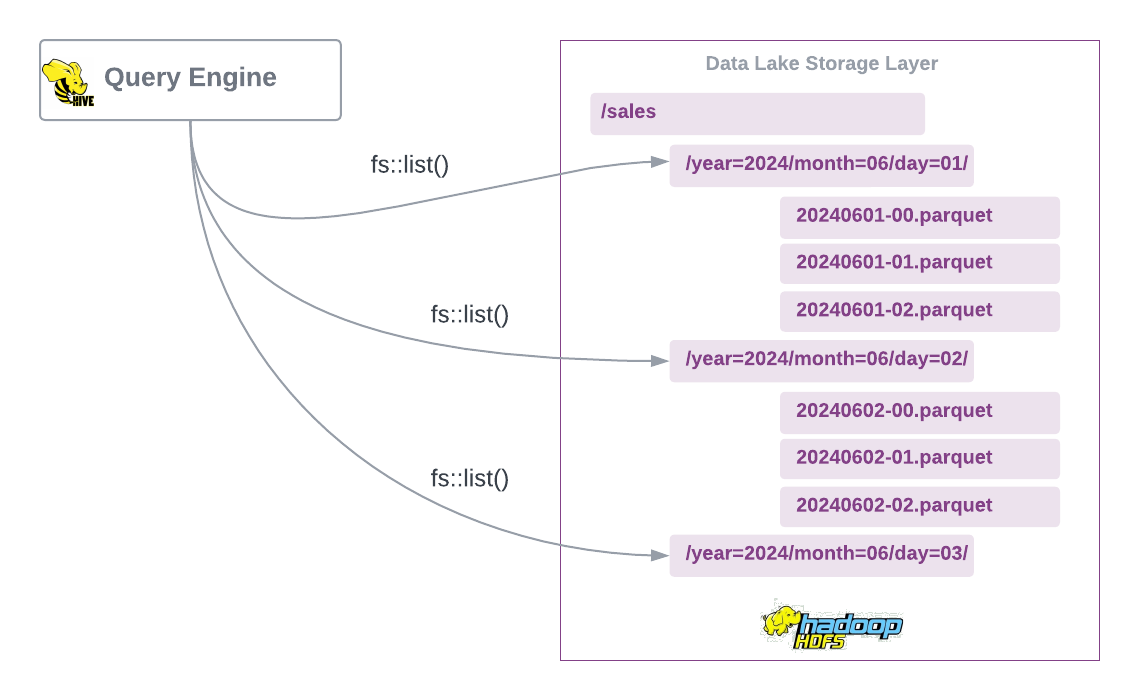
Now that we have covered what a directory-based table looks like, lets look at the Hive table format.
Hive Table Format
With the presented storage model, it’s fair to say that Apache Hive is a directory-oriented table format, relying on the underlying file system's API for mapping files to tables and partitions. Consequently, Hive is heavily influenced by the physical layout of data within the distributed file system.
Hive employs its own partitioning scheme, using field names and values to create partition directories. It manages schema, partition, and other metadata in a relational database known as the Metastore.
The Significant shift so far with Hive + Hadoop is:
Unlike traditional monolithic databases, Hadoop and Hive's decoupled approach allows other query and processing engines to process the same data on HDFS using Hive engine’s metadata.
Following example shows a typical Hive temporal partitioning based on year, month and day.
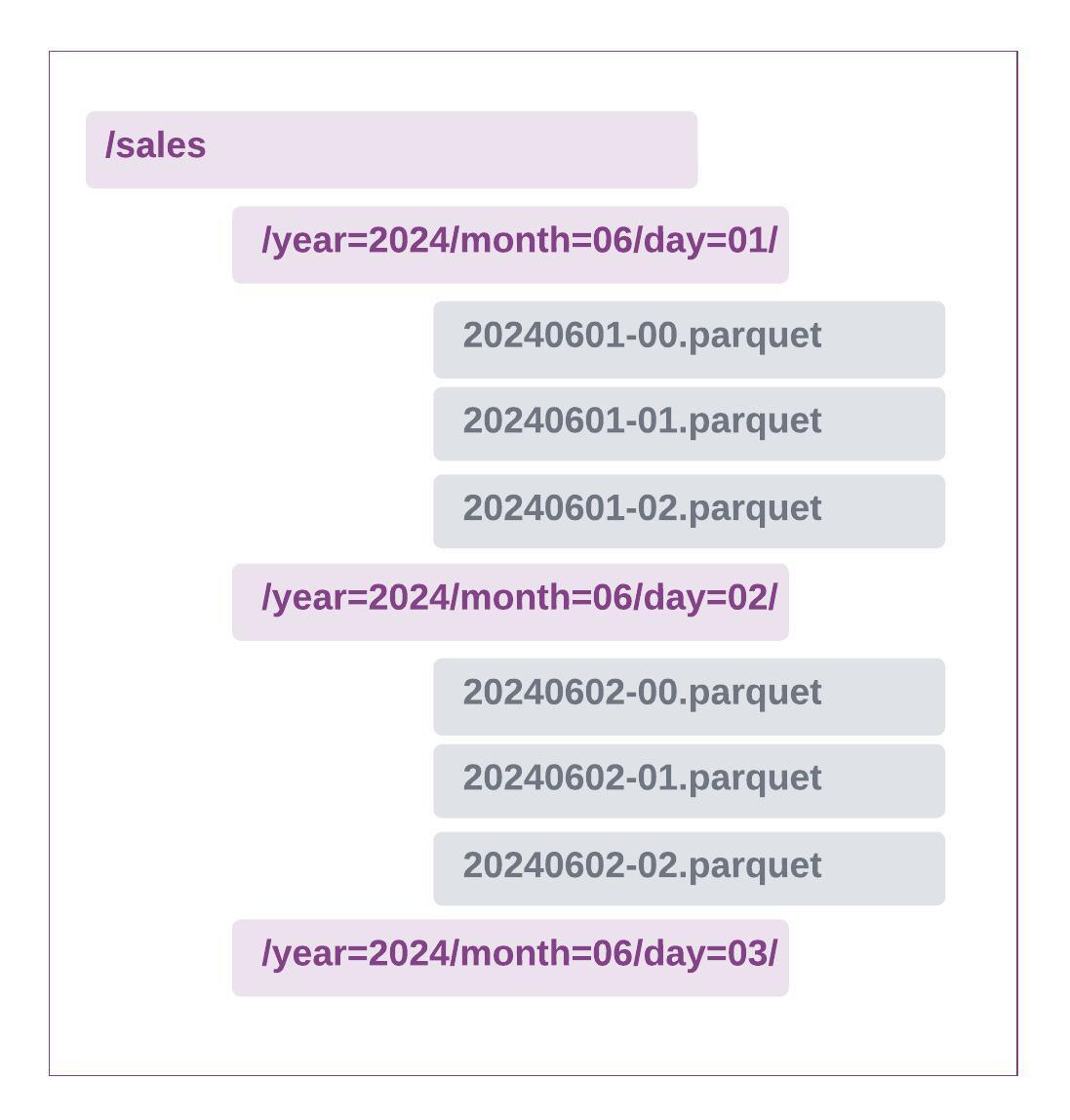
This leads to another major difference between the new data architecture and traditional DBMS systems: While traditional systems tightly bind data and metadata like table definitions, the new paradigm separates these components.
This decoupling offers great flexibility. Data can be ingested into data lakes without accompanying metadata, and multiple processing systems can independently assign their own metadata or table definitions to the same data.
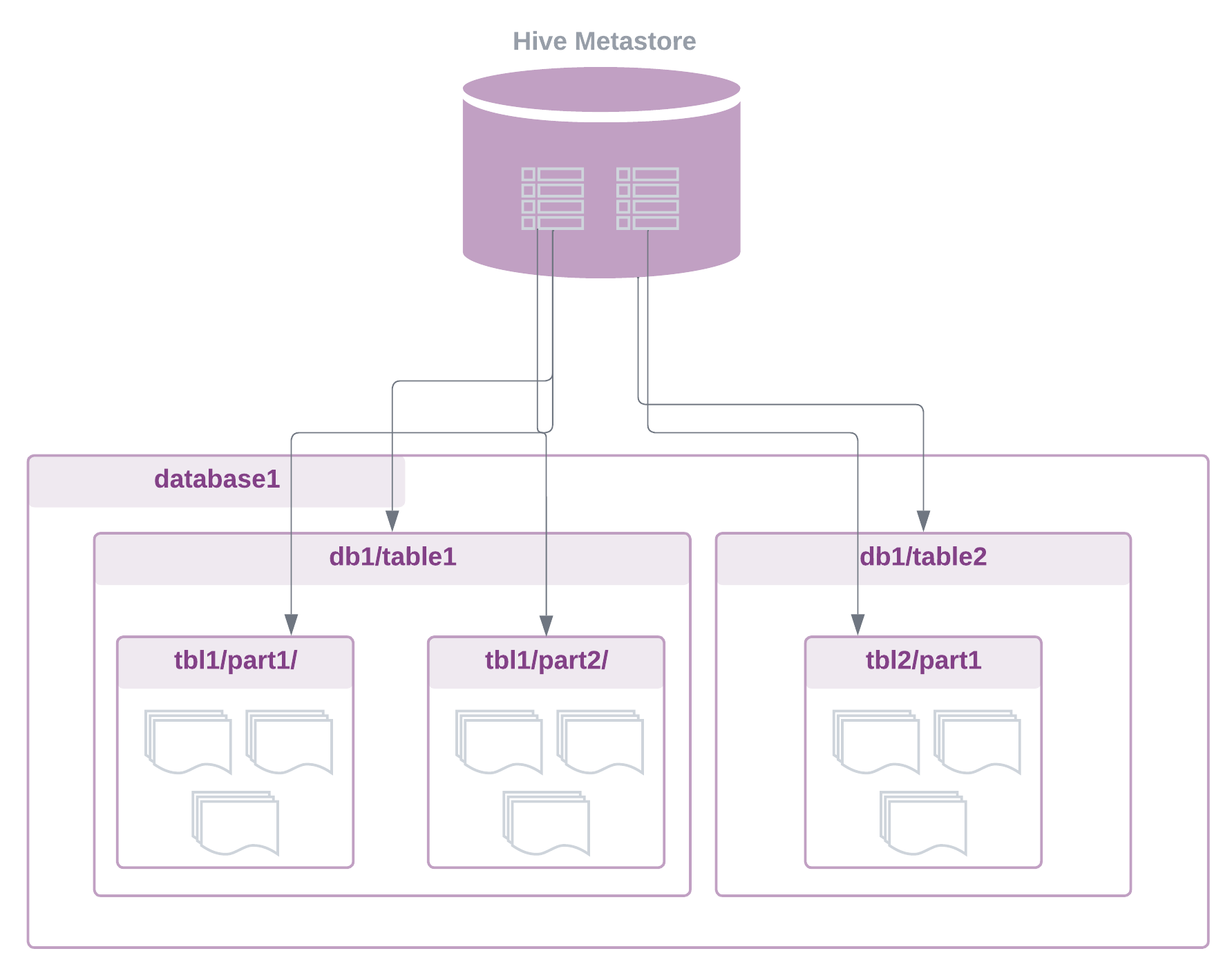
Moreover, a centralised schema registry (such as the Hive Metastore, which has become the de facto standard) allows any processing engine to interact with data in a structured tabular format, using familiar SQL or python languages using other computation frameworks such as Spark, Presto and Trino.
By accessing table metadata within the registry, query engines can determine file locations on the underlying storage layer, understand partitioning schemes, and execute their own read and write operations.
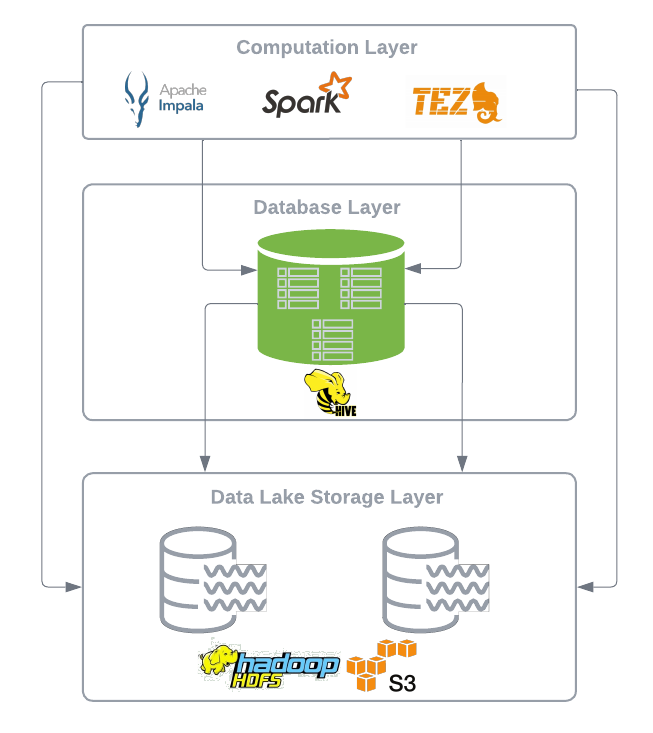
I hope you now understand why we refer to this design as open and perhaps begin to appreciate its flexibility and open architecture compared to previous generations of database systems.
Drawbacks and Limitations and the Directory-oriented and Hive table Format
For nearly a decade, from 2006 to 2016, Hive reigned supreme as the most popular table format on Hadoop platforms. Tech giants like Uber, Facebook, and Netflix heavily relied on Hive to manage their data.
However, as these companies scaled their data platforms, they encountered significant scalability and data management challenges that Hive couldn't adequately address.
Let's delve into the shortcomings of the directory-oriented table formats and Hive-style tables that prompted the engineers at this tech companies to seek alternatives.
First lets look at challenges and drawbacks of directory-oriented table format, the foundation upon which Hive has been developed:
High Dependency on Underlying File System - This architecture heavily relies on the underlying storage system to provide essential guarantees like atomicity, concurrency control, and conflict resolution. File systems lacking these properties, such as Amazon S3's absence of atomic rename, necessitate custom workarounds.
File Listing Performance - Directory and file listing operations can become performance bottlenecks, particularly when executing large-scale queries. Cloud object stores like S3 impose significant limitations on directory-style listing operations. Each LIST request returns a maximum of 1000 objects, necessitating multiple sequential requests, which can be slow due to latency and rate limiting. This significantly impacts performance when dealing with large datasets.
Query Planning Overhead - On distributed file systems like HDFS, query planning can be time-consuming due to the need for exhaustive file and partition listing. This is especially pronounced when dealing with a large number of files and partitions.
Drawbacks and challenges of using Hive-style partitioning:
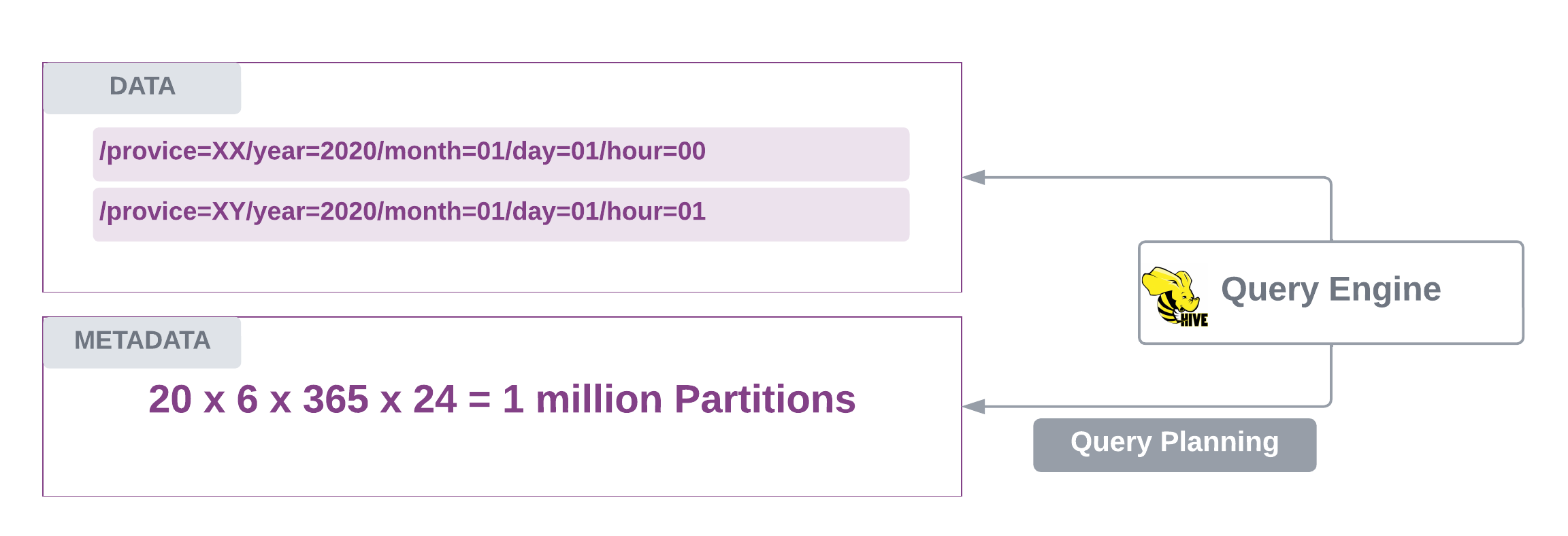
Over Partitioning - Tightly coupling physical and logical partitioning can lead to over-partitioning, especially with high-cardinality partition columns like
year/month/day. This results in excessive small files, increased metadata overhead, and slower query planning due to the need to scan numerous partitions. Over-partitioning is particularly detrimental to MPP engines like Hive, Spark, and Presto, as they struggle with query planning and scanning a large number of small partitions.Cloud Effect - Cloud data lakes exacerbate over-partitioning issues due to API call limitations. Jobs scanning many partitions and files often encounter throttling, leading to severe performance degradation.
Too Many Small Files - Incorrect partitioning schemes can create numerous small files, having negative impact on different layers, slowing down queries and job planning and re-partitioning requires rewriting the entire dataset, a costly and time-consuming process.
Poor Performance - Queries on Hive-style directory-based partitions can be slow without specifying the partition key for data skipping, especially with deep partition hierarchies. Accidental full table scans become common, leading to inefficient and lengthy query execution.
Accidental Costly Queries - Accidental full table scans can result in launching large queries and jobs. During my years of managing a Hadoop platform, I had to explain many times to end-users why their simple Hive query was taking a long time to run due to scanning large number of partitions during query planning phase.
Imagine a Hive table being partitioned by 20 provinces, followed by year=/month=/day=/hour= partitions. Such a table would accumulate over 1 million partitions in 6 years.
Drawbacks of using External Metastore
In addition to the above drawbacks, the Hive-style table using an external Metastore add more challenges into mix:
Performance Bottleneck - Both Hive and Impala rely on an external metadata store (typically a relational database like MySQL or PostgreSQL), which can become a performance bottleneck due to frequent communication for table operations.
Metadata Performance Scalability - As data volumes and partition counts grow, the Metastore becomes increasingly burdened, leading to slow query planning, increased load, and potential out-of-memory errors. These issues have been extensively documented and addressed by the community. Many companies such as Airbnb have experience Metastore performance challenges before upgrading their platform.
Single Point of Failure - The Metastore represents a single point of failure. Crashes or unavailability can cause widespread query failures. Implementing high availability is crucial to mitigate downtime.
Network latency - Network latency between the query engine and the external Metastore, as well as the underlying relational database, can impact overall performance.
Inefficient Statistics Management - Hive's reliance on partition-level column statistics, stored in the Metastore, can hinder performance over time. Wide tables with numerous columns and partitions accumulate vast amounts of statistical data, slowing down query planning and impacting DDL commands like table renaming.
A First-hand Experience
I have personally faced many of the above challenges working with Hive in production for many years. In a recent project our development team had to rename some large and wide managed Hive tables with about 10k partitions and the rename would just hang and not complete even after many hours.
After investigation I found that for each table there are about 300k statistical records stored which Hive is trying to gather details and update these records. Even after rebuilding the index on the stats table in PostgreSQL database, the issue didn't fully get resolved.
I believe I’ve made a pretty strong case against Hive table format and its underlying directory-oriented architecture. Apache Hive has served the big data community well for nearly a decade, but its time to improve and develop something more efficient and scalable.
Transactional Guarantees on Data Lakes
Before presenting the next evolution of table formats, let's also examine some common challenges associated with implementing database management systems on a data lake backed by distributed file systems such as HDFS or object stores like S3.
These challenges are not specific to Hive or any other data management tool but are generally related to the ACID and transactional properties of traditional DBMS systems.
Lack of Atomicity - Writing multiple objects simultaneously within a transaction is not natively supported, hindering data integrity.
Concurrency Control Challenges - Concurrent modifications to files within the same directory or partition can lead to data loss or corruption due to the absence of transaction coordination.
Absence of Transactional Features - Data lakes build on HDFS or object stores lack built-in transaction isolation and concurrency control, requiring organisations to relax consistency requirements or implement custom solutions. Without transaction isolation, readers can encounter incomplete or corrupt data due to concurrent writes.
For read and write isolation, downstream consumers would have to implement custom mechanisms to ensure data consistency by waiting for upstream batch data processing workload to complete before initiating their jobs.
Support for Record-Level Mutations - The immutable nature of underlying storage systems prevents direct updates or deletes at the record level in data files.
Object Store Challenges - Object stores like S3 historically lacked strong read-after-write consistency, prompting some organisations to use staging clusters (e.g., HDFS) as an intermediate step before final data placement. Additionally, the absence of atomic rename operations has posed challenges for distributed processing engines like Spark and Hive, which rely on temporary directories for data staging before finalising output.
Hive Transactional Tables
Hive ACID feature was the first attempt to introduce structured storage guarantees, particularly ACID transactions (Atomic, Consistent, Isolated, Durable), to the realm of immutable data lakes.
Released in Hive version 3 (2016), this feature marked a significant leap forward by providing stronger consistency guarantees like cross-partition atomicity and isolation. Additionally, it offered improved management of mutable data on data lakes through upsert functionality.
But addition of ACID to Hive didn’t solve the fundamental issues because:
Hive ACID tables remained rooted in the directory-oriented approach, relying on a separate metadata store for managing table-level information within the underlying data lake storage layer.
Several attempts were made to integrate Hive ACID into the broader data ecosystem. Hortonworks developed the Hive Warehouse Connector to enable Spark to read Hive transactional tables, initially relying on Hive LLAP component.
Cloudera later introduced Spark Direct Reader mode in 2020, allowing direct file system access without Hive LLAP dependency.
Despite these efforts, I would say Hive ACID didn't catch the imagination of the community as it failed to gain widespread adoption due to its underlying design limitations. Support for reading and writing Hive ACID tables remained inconsistent across the ecosystem, with many prominent tools like Presto offering limited or no support.
That’s the end of Part I. In Part II next generation open table formats will be discussed.