


The History and Evolution of Open Table Formats - Part II
From Hive to High Performance: A Journey Through the Evolution of Data Management on Data Lakes

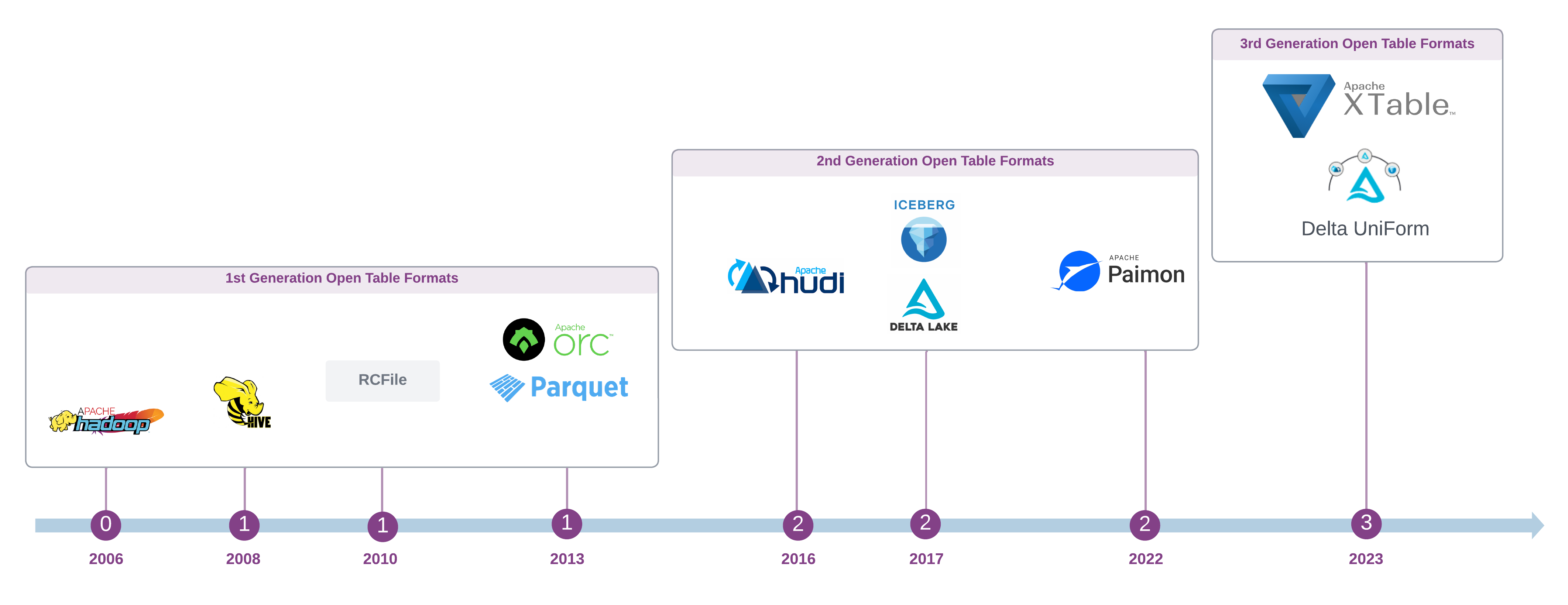
In Part I we went over the origin and architecture of traditional table management systems and the first generation of Open Table Formats (OTF). In this final part, I will discuss the second and third generation OTFs.
2nd Generation OTF - The Rise of Log-oriented Table Format
Now that we have built a strong case for re-imagining and improving the open table format model, let's recap and list the major issues we identified with the previous generation of table formats:
Tight coupling between physical partitioning and the logical partitioning scheme of the data.
Heavy reliance on the file system or object store API for listing files and directories during the query planning phase.
Relying on an external metadata store for maintaining table-level information such as schemas, partitions, and column-level statistics.
Lack of support for record-level upsert, merge and delete.
Lack of ACID and transactional properties.
Let's temporarily set aside the complexities of upsert and ACID transactions to focus on first three fundamental challenges. Given these constraints, we must consider how to decouple partitioning schemes from physical file layouts, minimise file system API calls for file and partition listings, and eliminate the reliance on an external metadata store.
To address these requirements, we need a data structure capable of efficiently storing metadata about data, partitions, and file listings. This structure must be fast, scalable, and self-contained, with no dependencies on external systems.
One solution to address these requirements is surprisingly simple, though not always the most obvious. Just as Jay Kreps and the engineering team at LinkedIn built Apache Kafka on the foundation of a simple append-only storage abstraction—an immutable log containing sequential records of events ordered by time— can we consider using a similar framework?
So the question is:
If immutable logs can store events representing facts that always remain true, effectively capturing the evolution of an application's state over time in systems like Apache Kafka, can't we apply the same basic principles to manage the state of table's metadata in our case?
By leveraging log files, we can treat all metadata modifications as immutable, sequentially ordered events. This aligns with the Event Sourcing data modeling paradigm, where we capture state changes at the partition and file level within transactional logs stored alongside the data.
Files and partitions become the unit of record for which the metadata layer tracks all the state changes in the log. In this design, the metadata logs are the first class citizens of the metadata layer.
Lets build a Simple Log-oriented Table
Let’s do a quick practical exercise to understand how we can design our new table format to capture and organise the metadata in log files.
In this exercise we will build a simple log-oriented metadata table format for capturing the filesystem and storage-level state changes such as adding and removing files and partitions, which can provide the event log primitives such as strong ordering, versioning, time travel and replaying event to rebuild the stage.
For capturing storage-level or file system state changes we need to consider two main file system objects, that is files and directories (i.e partitions) with following possible events:

Let’s assume a particular table contains three partitions in /year=/month=/day= format. In a most simple form, the metadata log can be implemented with following fields in an immutable log file:
timestamp|object|event type|value
20231015132000|partition|add|/year=2023/month=10/day=15
20231015132010|file|add|/year=2023/month=10/day=15/00001.parquet
20231015132011|file|add|/year=2023/month=10/day=15/00002.parquet
20231015132011|file|add|/year=2023/month=10/day=15/00003.parquetLater if a file is removed, a new remove event can be captured at the end of the log file:
20231015132011|file|remove|/year=2023/month=10/day=15/00003.parquetManaging Metadata Updates
Given the immutable nature of data lake storage systems like HDFS or object stores, metadata logs cannot be continuously appended to. Instead, each update resulting from data manipulation operations (e.g., new data ingestion) requires the creation of a new metadata file.
To maintain sequence and facilitate table state reconstruction, these metadata logs can be sequentially named and organised within a base metadata directory.
/mytable/
/metadata_logs/
000001.log
000002.log
000003.log
000004.logIn order to rebuild the current table state, the order of the metadata logs in the metadata directory, and possibly the Timestamp field in the logs, can serve as the physical or logical clock which can provide strong sequential ordering semantics for replaying metadata events.
The query engines can scan the event log sequentially to replay all the metadata state change events in order to rebuild the current snapshot view of the table.
Log Compaction
Frequent data updates on large datasets can lead to a proliferation of metadata log files, as each change necessitates a new log entry.
Over time, the overhead of listing and processing these files during state reconstruction can become a performance bottleneck, negating the benefits of decoupling metadata management.
To mitigate this, a compaction process can merge individual log files into a consolidated file, removing obsolete records like superseded add and remove events. However, for time travel and rollback capabilities, these outdated events must be retained for a specified period.
By periodically executing background compaction jobs, we can generate snapshot logs encapsulating all essential state changes up to a specific point in time.
/mytable/
/metadata_logs/
000001.log
000002.log
000003.log
000004.log
snapshot_000004.log
000005.logIn the above example, the snapshot log snapshot_000004.log has been generated for sequential log files 000001.log to 000004.log containing all the metadata transactions up to that point. To get the current table snapshot view, the latest snapshot file along with any additional new delta log files need to be scanned, which is now more optimised and efficient.
What did we just build?
We've successfully designed a foundational log-oriented table format that addresses our initial requirements by using simple, immutable transactional logs to manage table metadata alongside data files.
This approach serves as the bedrock for modern open table formats like Apache Hudi, Delta Lake, and Apache Iceberg.
Essentially:
The modern open table formats provide a mutable table abstraction layer on top of immutable data files through a log-based metadata layer, offering database-like features such as ACID compliance, upserts, table versioning, and auditing.
This architectural shift marks a significant departure from previous table implementations by eliminating heavy reliance on the underlying storage system's metadata API, a potential performance bottleneck in large-scale data lakes.
By abstracting the physical file layout and tracking the table state (including partitions) at the file level within the metadata layer, these formats decouple logical and physical data organisation using the log-oriented metadata layer as shown below.
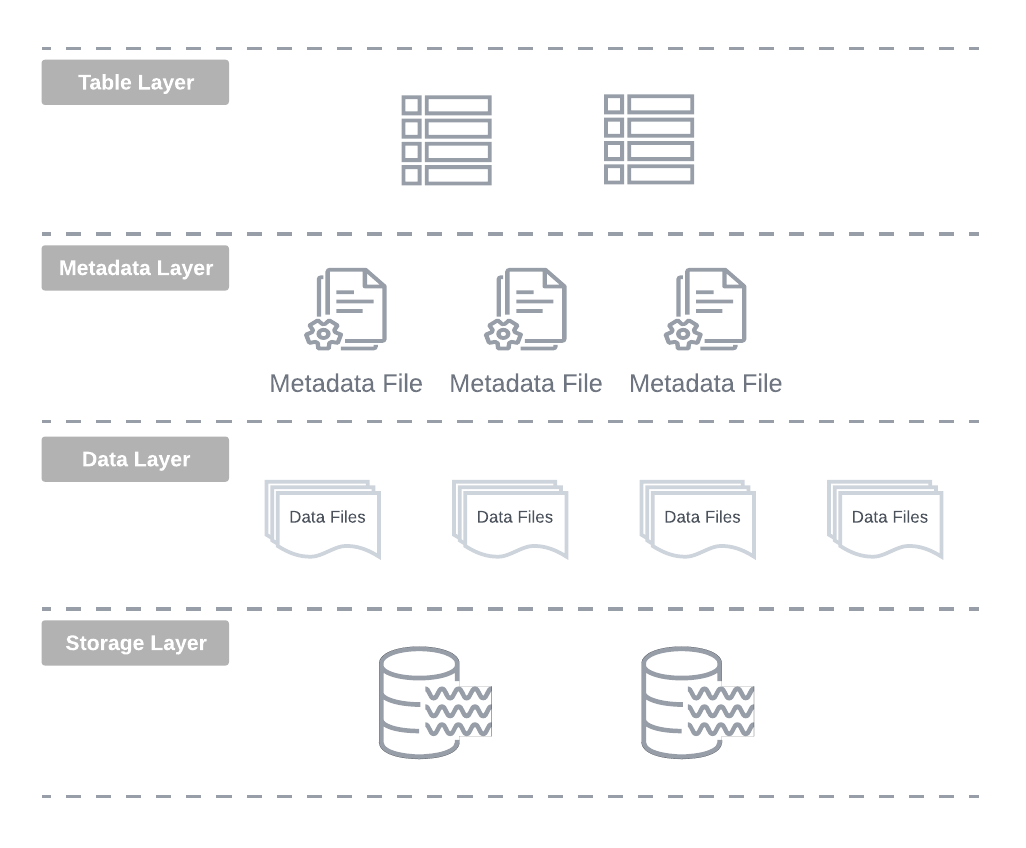
What about query performance?
In this architecture, the query performance is directly affected by how fast the required metadata can be retrieved and scanned during the query planning phase.
Using the underlying storage fast sequential I/O for reading metadata files provides much better performance that using their metadata APIs for gathering the required details such as the list of all sub-directories (partitions), files and retrieval of column-level statistics either from the footer section of the data files, or from the external metadata engine.
Is this a Novel Design?
The concept of using metadata files to track data files and associated metadata isn't entirely novel.
Key-value stores like RocksDB and LevelDB employ a similar approach, using manifest files to keep track of SSTables (data segments in LSM-Tree storage model) and their corresponding key ranges. These manifest files are cached in memory, enabling rapid identification of relevant SSTables without exhaustive directory scans suing the underlying storage APIs [1].
I wonder if those smart engineers behind the modern open table formats drew any inspirations from metadata management design in storage systems like RocksDB!
Adding Additional Feature
By adopting an event log and event sourcing model, we can readily implement additional valuable primitives:
Event Replay - The ability to replay file and directory change event logs up to a specific version.
Full State Rebuild - Compute engines can reconstruct the table's current state and identify active files and partitions by processing the metadata event log.
Time Travel - Similar to event-based systems, we can revert to previous table versions using the event log and versioning mechanism.
Event-Based Streaming Support - The transactional log inherently functions as a message queue, enabling the creation of streaming pipelines without relying on separate message buses.
Recall how Apache Hive manages column-level statistics (e.g., min/max values) for each table partition by storing records in a metadata database to optimize query performance. While binary formats like ORC and Parquet include file-level statistics, eliminating the need to query the Metastore, this approach still requires scanning and loading file footers during query planning, impacting scalability.
To address this, we can leverage our log-based metadata layer to store additional statistical metadata, optimising query performance by avoiding external system interactions and extensive file footer scans.
By consolidating file-level statistics into a small set of index files, we aim to reduce the I/O overhead associated with query planning from linear scaling (O(n)) to near-constant time (O(1)).
We could essentially follow the same metadata organisation, but use different naming conventions to manage column stats index. For each new data file loaded, a new delta index log can be generated to save the column stats records. When a compaction job runs to consolidate the metadata logs, it can also perform compaction on the column index logs to generate a snapshot file.
/mytable/
/metadata_logs/
stats_000001.log
stats_000002.log
stats_000003.log
stats_000004.log
stats_snapshot_000004.log
stats_000005.logUsing a Consolidated Log File
By adopting a more structured file format capable of handling nested structures like JSON or Avro, we can optimise our design by consolidating all metadata within a single metadata file. This unified approach simplifies metadata management and reduces I/O overhead compared to managing multiple log files.
Furthermore, a single schema can be used to encapsulate different metadata types, streamlining the overall structure. To differentiate between metadata sets, we can employ a nested structure with distinct keys similar to following:
files:[
{timestamp:20231015132000,type:partition,action:add,details:/. data=20231015},
{timestamp:20231015132000,type:file,action:add,details:/data=20231015/00001.parquet}
]
stats:[
{timestamp:20231015132000,partition:/data=20231015,filename:00001.parquet,column_name:price,column_type:float,min:5,max:20},
{timestamp:20231015132000,partition:/data=20231015,filename:00001.parquet,column_name:product,column_type:string,min:book,max:pen},
]The above design is similar to how Apache Hudi manages the metadata in HFiles format. Another possible format is to use a single object for each data file containing all the related metadata using nested entries:
{
"timestamp": 20231015132000,
"type": "file",
"action": "add",
"details": "/data=20231015/00001.parquet"
"column_stats":[
{"column_name":"price","column_type":"float","min":5,"max":20}, {"column_name":"product","column_type":"string","min":"book","max":"pen"}
]
}This is the format that Delta Lake uses by storing column-level statistics as a nested structure inside the main JSON transactional logs, under stats index.
Adding ACID Guarantees
A core design objective of open table formats is to enable ACID guarantees through the metadata layer. The new log-structured metadata approach inherently supports functions such as versioning and Snapshot Isolation via MVCC, addressing the previously discussed transaction isolation challenges in data lakes.
To provide Snapshot Isolation, writes can occur in following two steps:
Optimistically create or replace data files, or delete existing files on the underlying storage.
Atomically update the metadata transaction log with the newly added or removed files, generating a new metadata version.
This transactional mechanism prevents readers from encountering incomplete or corrupt data, a common issue in the previous table format generation, ensuring data integrity. By bypassing file system listing operations, we eliminate consistency issues like list-after-write on some object stores.
All three major table formats (Hudi, Delta Lake, Iceberg) implement MVCC with snapshot isolation to provide read-write isolation and versioning. They maintain multiple table versions as data changes, allowing readers to select files from the most recent consistent snapshot using the transaction log.
Multi-Write Concurrency can be facilitated through Optimistic Concurrency Control (OCC), which validates transactions before committing to detect potential conflicts. If concurrent writes target non-overlapping file sets, they can proceed independently.
However, if there's overlap, only one write succeeds while others are aborted during conflict resolution. All three major table formats employ some form of Optimistic Concurrency Control to manage concurrent writes and identify conflicts effectively.
The Origin of Modern Open Table Formats implementations
As previously discussed, the current generation of open table formats emerged to address the limitations of the previous generation of data management approaches on data lakes, and the foundation of these tools lies in the log-structured metadata organisation explored earlier.
Apache Hudi, initiated by Uber in 2016, primarily aimed to enable scalable, incremental upserts and streaming ingestion into data lakes, while providing ACID guarantees on HDFS. Its design is heavily optimised for handling mutable data streams. The traditional snapshot and batch ingestion patterns used with Hive-style tables proved inadequate for low-latency use cases. An incremental approach that focused on new and updated data was necessary, but the immutability of HDFS posed challenges.
Apache Iceberg originated at Netflix around 2017 in response to the scalability and transactional limitations of Hive's schema-centric, directory-oriented table format. The realisation that incremental improvements to Hive were insufficient drove the development of a new solution by changing the table design to instead track data in a table at the file level by pointing the table to an ordered list of files. Iceberg was born from this insight and employs a manifest-based metadata layer consisting of metadata, manifest list, and manifest files organised hierarchically.
Delta Lake, introduced by Databricks in 2017 and open-sourced in 2019, emerged as the third major open table format. Its primary goal was to provide ACID transaction capabilities atop cloud object store-based data lakes. This was motivated by the absence of ACID guarantees, including cross-object consistency and query isolation, within cloud object stores.
Apache Paimon is another notable and fairly recent open table format developed by the Apache Flink community in 2022, as the "Flink Table Store" and a lakehouse streaming storage layer with the main design goal of handling high throughput and low latency streaming data ingestion. However it has yet to gain any significant traction in comparison to the dominant trio.
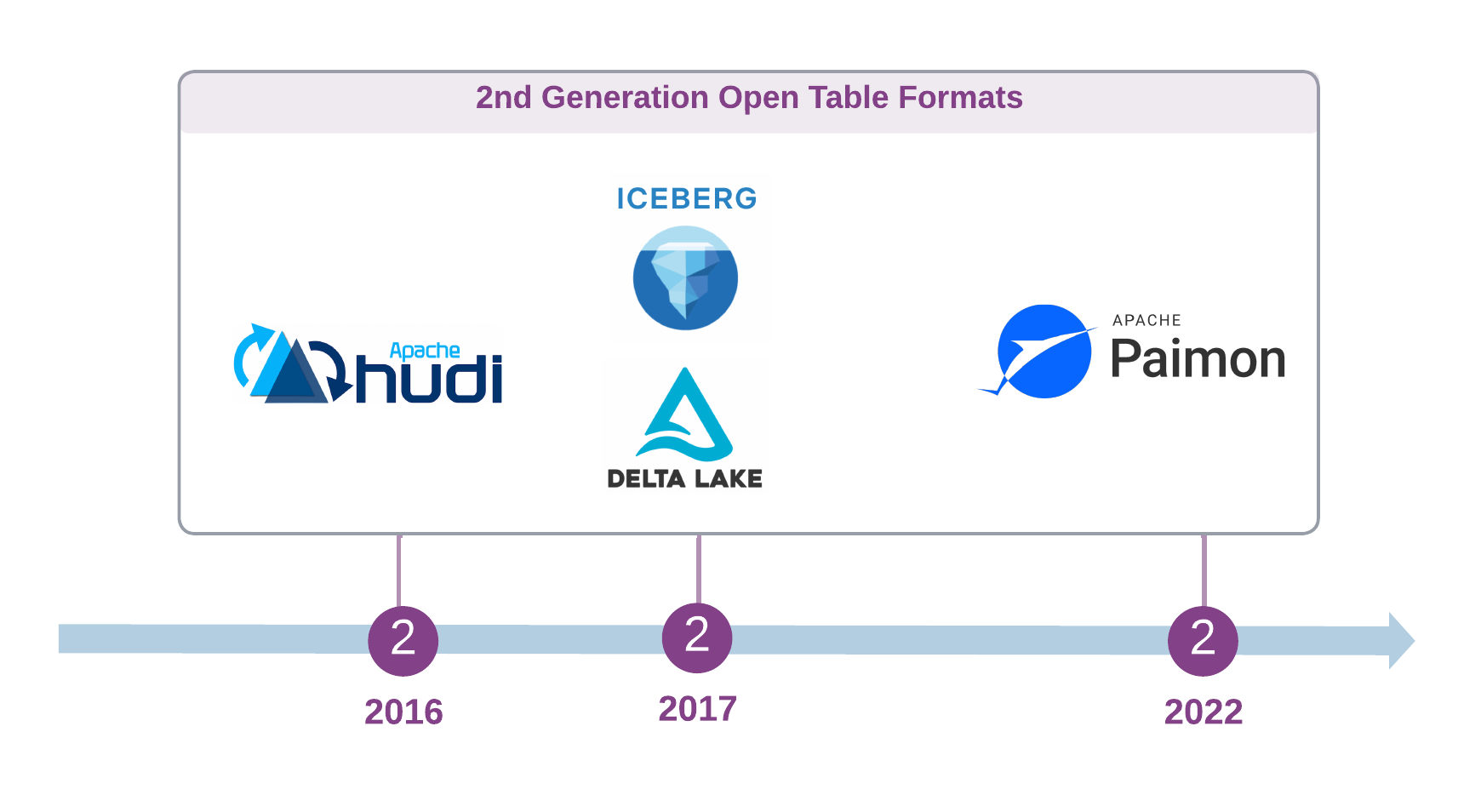
These projects have significantly streamlined data management for users by automating optimisations, compaction, and indexing processes. This relieves data engineers from the burden of complex low-level physical data management tasks.
In Part 1 we questioned whether we could build a system that can combine the benefits of the traditional monolithic DBMS and disaggregated data lake systems. We can now declare that what we have is:
A powerful combination of the encapsulation and abstraction found in traditional DBMS physical layers with the openness, interoperability, and flexibility of modern open table formats.
Industry Adoption
The past few years have witnessed widespread adoption and integration of next-generation open table formats across various data tools and platforms.
All the major open table formats have gained traction and popularity while a fierce competition for market dominance has been going on mainly by the SaaS vendors providing these products as a managed service.
Major cloud providers have also embraced one or all of the big three formats, with Microsoft fully committing to Delta Lake for its latest OneLake and Microsoft Fabric analytics platforms, and Google adopting Iceberg as the primary table format for its BigLake platform. Cloudera, a leading Hadoop vendor, has also built its open data lakehouse solution around Apache Iceberg.
Prominent open source compute engines like Presto, Trino, Flink, and Spark now support reading and writing to these open table formats. Additionally, major MPP and cloud data warehouse vendors, including Snowflake, BigQuery, and Redshift, have incorporated support through external table features.
Beyond these tools and platforms, numerous companies have publicly documented their migration to open table formats.
3rd Generation OTF - Unified Open Table Format
The evolution of open table formats has marched on with a new trend since last year: cross-table interoperability.
This exciting development aims to create a unified and universal open table format that seamlessly works with all major existing formats under the hood.
Currently, converting between formats requires metadata translation and data file copying. However, since these formats share a foundation and often use Parquet as the default serialisation format, significant opportunities for interoperability exist.
A uniform metadata layer promises a unified approach for reading and writing data across all major open table formats. Different readers and writers would leverage this layer to interact with the desired format, eliminating the need for manual format-specific metadata conversion or data file duplication.
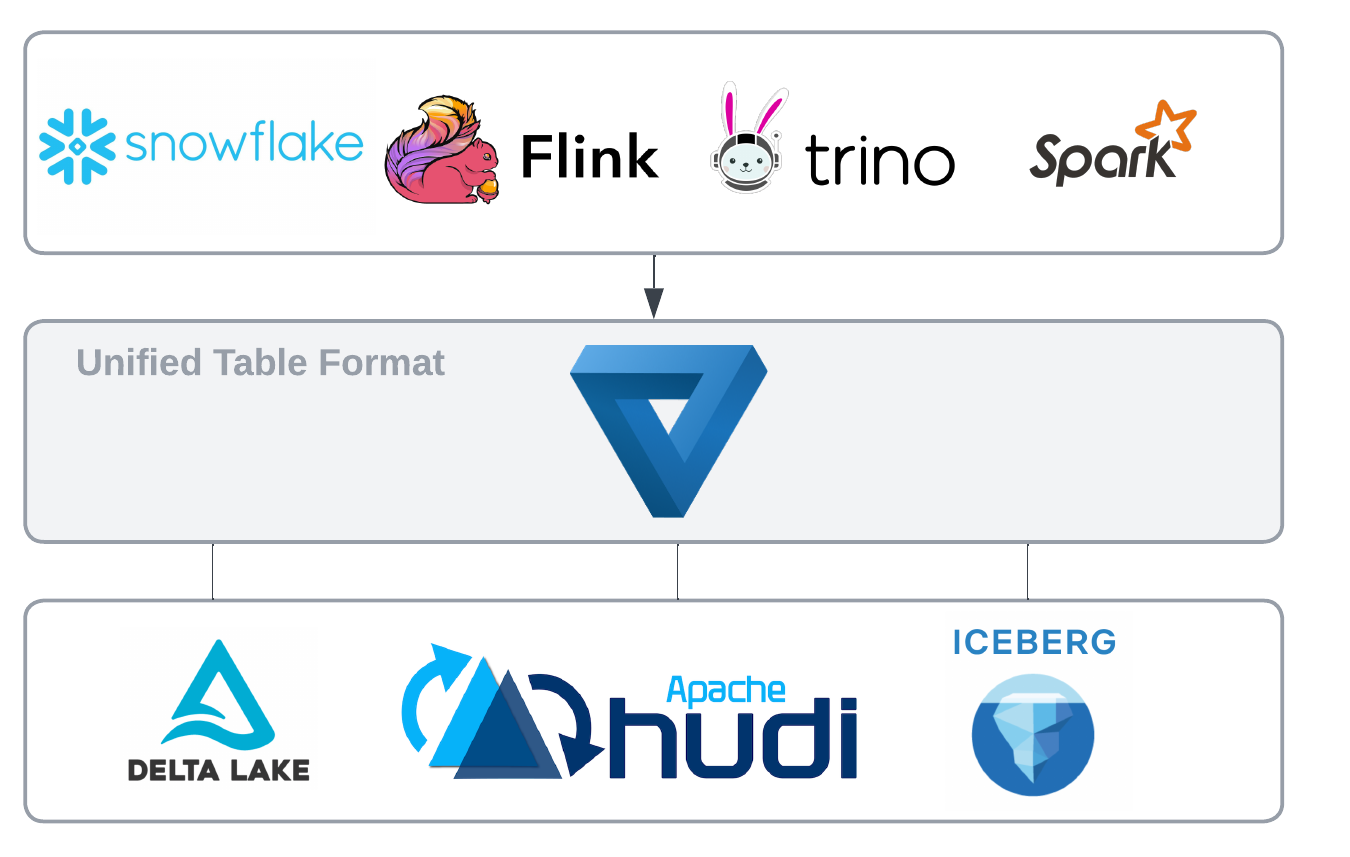
The State of Art
LinkedIn engineers pioneered one of the earliest attempts at a unified table API with OpenHouse introduced in 2022. Built on top of Apache Iceberg, OpenHouse offered a simplified interface for interacting with tables, regardless of their underlying format, through a RESTful Table Service seamlessly integrated with Spark.
While OpenHouse was a great effort, it lacked comprehensive interoperability and format conversion capabilities. Additionally, its open-sourcing in 2024 came relatively late compared to other emerging projects that had already gained significant traction, specially with giant tech companies such as Databricks, Microsoft and Google backing following projects.
Apache XTable (formerly known as OneTable), introduced by OneHouse in 2023, provides a lightweight abstraction layer for generating metadata for any supported format using common models for schemas, partitioning details, and column statistics. In terms of metadata layout, XTable stores metadata for each format side-by-side within the metadata layer.
XTable uses the latest snapshot of the primary table format, and generates additional metadata for target formats. Consumers can either use the primary format, or the target formats to read and write and get the same consistent view of the table’s data.
Databricks introduced Delta UniForm in 2023. Delta UniForm automatically generates metadata for Delta Lake and Iceberg tables while maintaining a single copy of shared Parquet data files. It's important to note that UniForm, primarily sponsored by Databricks, seems focused on using Delta Lake as the primary format while enabling external applications and query engines to read other formats.
How do they compare?
LinkedIn's OpenHouse project offers more of a control plain than a unified table format layer.
Comparing Apache XTable to Delta Uniform, XTable takes a broader approach, aiming for full interoperability and allowing users to mix and match read/write features from different formats regardless of the primary format chosen.
As an example, XTable could enable incremental data ingestion into a Hudi table (leveraging its efficiency) while allowing data to be read using Iceberg format by query engines like Trino, Snowflake, or BigQuery.
That being said, we're still in the early phases of development of uniform table format APIs. It will be exciting to see how they progress over the coming months.
Data Lakehouse
That brings us to the last part of this blog post to explore the concept of a data lakehouse without which our discussion would be incomplete. Let’s define what a data lakehouse stands for:
A data lakehouse represents a unified, next-generation data architecture that combines the cost-effectiveness, scalability, flexibility and openness of data lakes, with the performance, transactional guarantees and governance features typically associated with data warehouses.
That definition sounds very similar to what open table formats stand for! That’s because the lakehouse foundation is based on leveraging open table formats for implementing ACID, auditing, versioning, and indexing directly on low-cost cloud storage, to bridge the gap between these two traditionally distinct data management paradigms.
In essence, data lakehouse enables organisations to treat data lake storage as if it were a traditional data warehouse and vice versa. They offer the flexibility and decoupled architecture of data lakes—allowing for the storage of unstructured and semi-structured data in open formats and the use of diverse compute engines—combined with the performance, transactional capabilities, and full CRUD operations characteristic of data warehouses.
This vision was initially pursued by SQL-on-Hadoop tools to bring data warehousing to Hadoop platforms, but only getting fully realised recently with the advancements in the data landscape.
Non-Open vs Open Data Lakehouse
It's crucial to differentiate between a general "data lakehouse" and an "open data lakehouse".
While top cloud vendors like AWS and Google often label their data warehouse-centric platforms as data lakehouses, their definition is broader.
Their emphasis is on their data warehouses' ability to store semi-structured data, support external workloads like Spark, enable ML model training, and query open data files—all characteristics traditionally associated with data lakes. These platforms also typically feature decoupled storage and compute architectures.
It was around 2020-2021 Amazon started promoting a lake house concept comprised of Amazon Redshift data warehouse implemented over new RA3 managed storage, plus Redshift Spectrum, before the wider adoption of the "lakehouse" term by other vendors like Databricks and the data community in general, as a new approach to data warehousing.
Google has similarly promoted its analytics lakehouse architecture, outlined in a whitepaper published in 2023, providing a blueprint for building a unified analytics lakehouse using either BigQuery as the first choice, or open Apache Iceberg and BigLake platform.
On the other hand, open data lakehouse primarily leverage open table formats to manage data on low-cost data lake storage. This architecture promotes higher interoperability and flexibility, allowing organisations to select the optimal compute and processing engine for each job or workload.
By eliminating the need to duplicate and move data across systems, open data lakehouses ensure that all data remains in its original, open format, serving as a single source of truth.
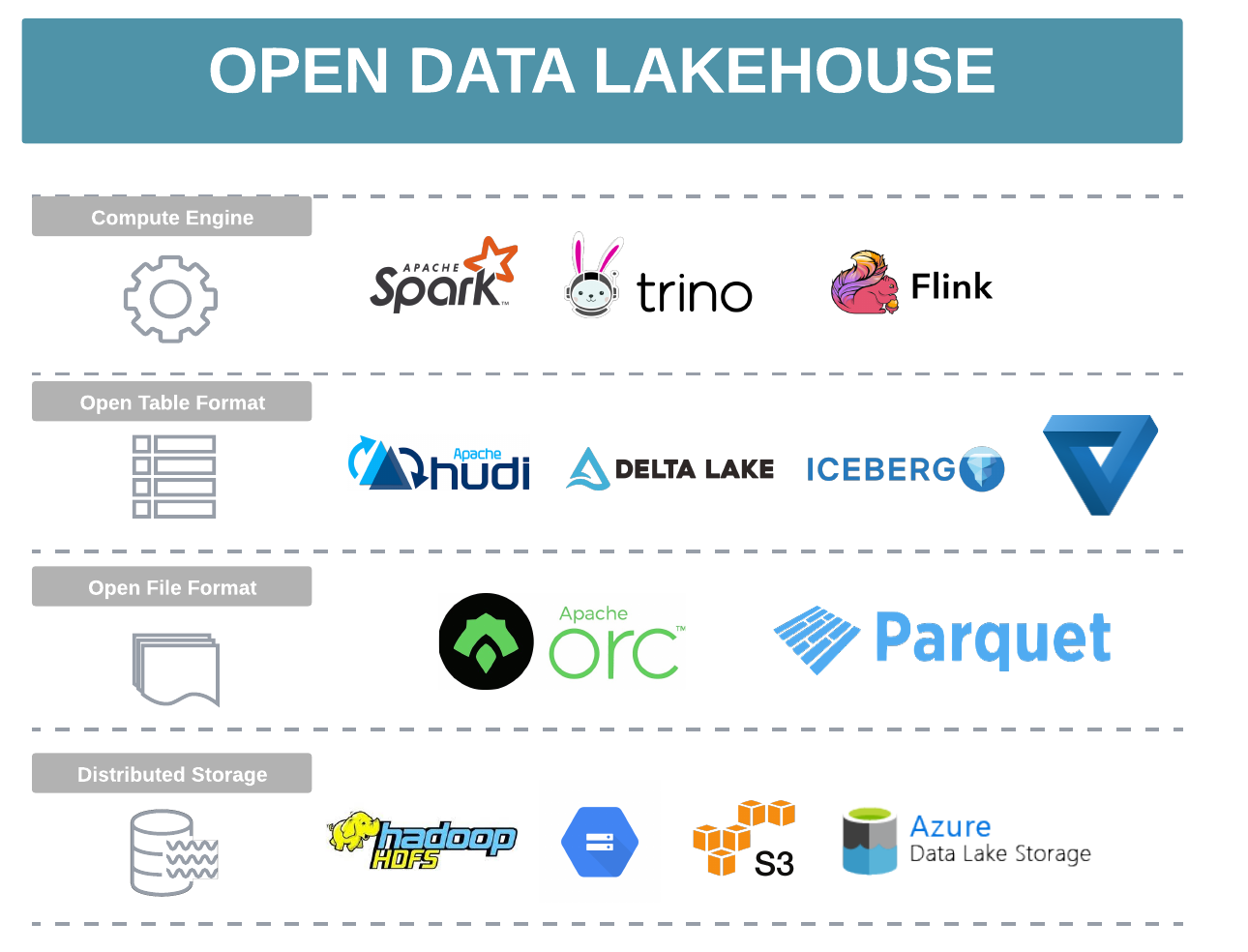
Vendors such as Databricks, Microsoft OneLake, OneHouse, Dremio, and Cloudera have positioned themselves as providers of managed open data lakehouse platforms on cloud.
Conclusion
This post series has covered a lot of ground, taking you on a journey through the evolution of data.
I am personally always interested in understanding how a technology came to be, the major architectural changes and evolutions it underwent, and the design goals and motivations behind it.
I hope you have enjoyed the ride and now have a better understanding of where we are in the technology timeline and how we got here.
References
[1] Dong, S., Callaghan, M., Galanis, L., Borthakur, D., Savor, T., & Strum, M. (2017, January). Optimizing Space Amplification in RocksDB. In CIDR (Vol. 3, p. 3).