


The Rise of Single-Node Processing: Challenging the Distributed-First Mindset
Data Landscape Trends: 2024-2025 Series

This is part two of Data Landscape Trends 2024-2025 series, focusing on single-node processing trends.
Introduction
2024 witnessed growing interest in single-node processing frameworks, with tools like DuckDB, Apache DataFusion, and Polars receiving increased attention and gaining unprecedented popularity from the data community.
This trend represents more than just a technological advancement—it marks a fundamental reassessment of how we approach data analytics.
As we move away from the "big data" era's distributed-first mindset, many businesses are discovering that single-node processing solutions often provide a more efficient, cost-effective, and manageable approach to their analytical needs when their size of data is not that big.
When I recently published a short post on LinkedIn titled "Why Single-Node Engines Are Gaining Ground in Data Processing", I didn’t anticipate the significant attention it would receive from the LinkedIn data community. This response underscored the industry’s increasing interest in the topic.
In this article, I will dive deeper into the subject, exploring it in greater detail and providing further insights.
Rethinking Big Data
The past decade saw many businesses scrambling to implement big data strategies, with many companies investing heavily in distributed processing frameworks like Hadoop and Spark.
However, recent analyses reveal a surprising truth: most companies don't actually have "big data".
A significant majority of companies do not require large data platforms to address their data analytics needs. Often, these companies are swayed by marketing hype and make substantial investments in these platforms, which may not effectively resolve their actual data challenges.
Jordan Tigani, a founding engineer on Google BigQuery, analysed usage patterns and found that the median data storage size among heavy BigQuery users is less than 100 GB.
Even more revealing, an analysis of half a billion queries run on Amazon Redshift published in a paper showed that:
Over 99% of queries processed less than 10 TB of data.
Over 90% of sessions processed less than 1 TB.
The paper also states that:
Most tables have less than a million rows and the vast majority (98 %) has less than a billion rows. Much of this data is small enough such that it can be cached or replicated.
This analysis reveals that with a big data processing threshold of 1 TB, over 90% of queries fall below this threshold.
As a result, single-node processing engines have the potential to handle workloads that previously required distributed systems like Spark, Trino, or Amazon Athena to process across multiple machines.
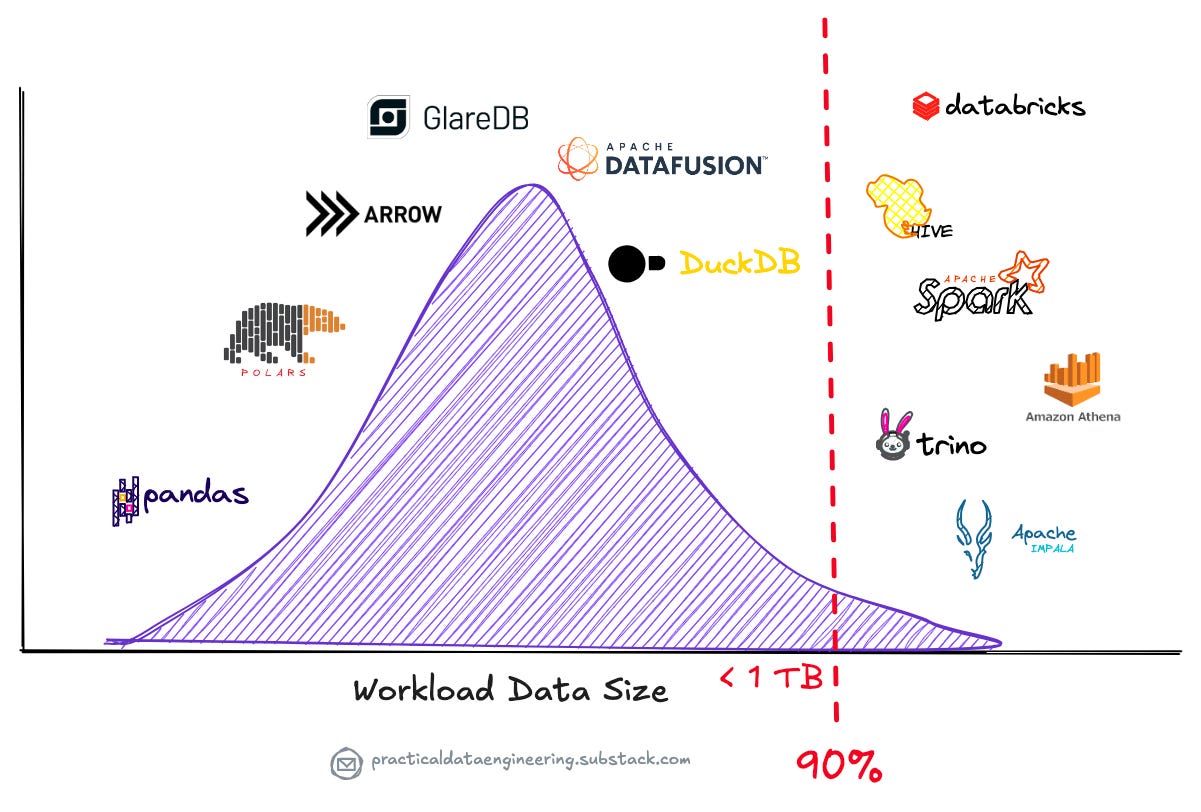
This reality challenges the common notion that big data infrastructure is a necessity for all modern businesses.
Workload Patterns & Rapid Data Aging
The case for single-node processing becomes even more compelling when we examine how organisations actually use their data.
Two key patterns emerge: the data aging effect and the 90/10 rule of analytical workloads.
The Data Aging Effect
As data ages, access frequency declines sharply. For the majority of companies, data access patterns follow a predictable lifecycle:
Hot data (0-48 hours): primarily from ETL pipelines.
Warm data (2-30 days): Accounts for most analytical queries.
Cold data (30+ days): Rarely accessed but often retained for compliance or historical analysis.
A study of Meta and eBay's data access patterns revealed this sharp decline in access after the first few days, with data typically becoming cold after a month.
In our analysis of a petabyte-scale data lake, we found that raw data remains hot for only 48 hours, with 95% of access occurring in that time, mainly by downstream ETL pipelines. In Analytics (Gold) zone, the hot period lasts about 7 days, and 95% of queries are executed only within 30 days.
The 90/10 Rule for Analytical Workloads
This aging effect leads to the 90/10 rule in analytical workloads:
If the combined hot and warm period is 30 days accounting for 90% of workloads, then, with a one-year retention period, over 90% of workloads access fewer than 10% of the data.
This pattern holds remarkably consistent across industries and use cases. Even in organisations with large datasets, most analytical workloads operate on recent, aggregated data that could easily fit within single-node processing capabilities.
Hardware Evolution & Rethinking Scale Up
The capability of single-node systems has grown exponentially since the early days of big data.
The rationale and motivation behind the scale-out strategy which became popular with emergence of Hadoop in mid 2000s in data processing is the necessity of combining multiple machines to address scaling challenges, enabling efficient processing of large datasets within reasonable timeframes and performance levels.
By integrating multiple machines in distributed systems, we effectively create a single large unit, pooling resources such as RAM, CPU, disk space, and bandwidth into one large virtual machine.
However, we need to reassess our assumptions about distributed processing and the scaling challenges faced in the 2000s to see if they remain valid today.
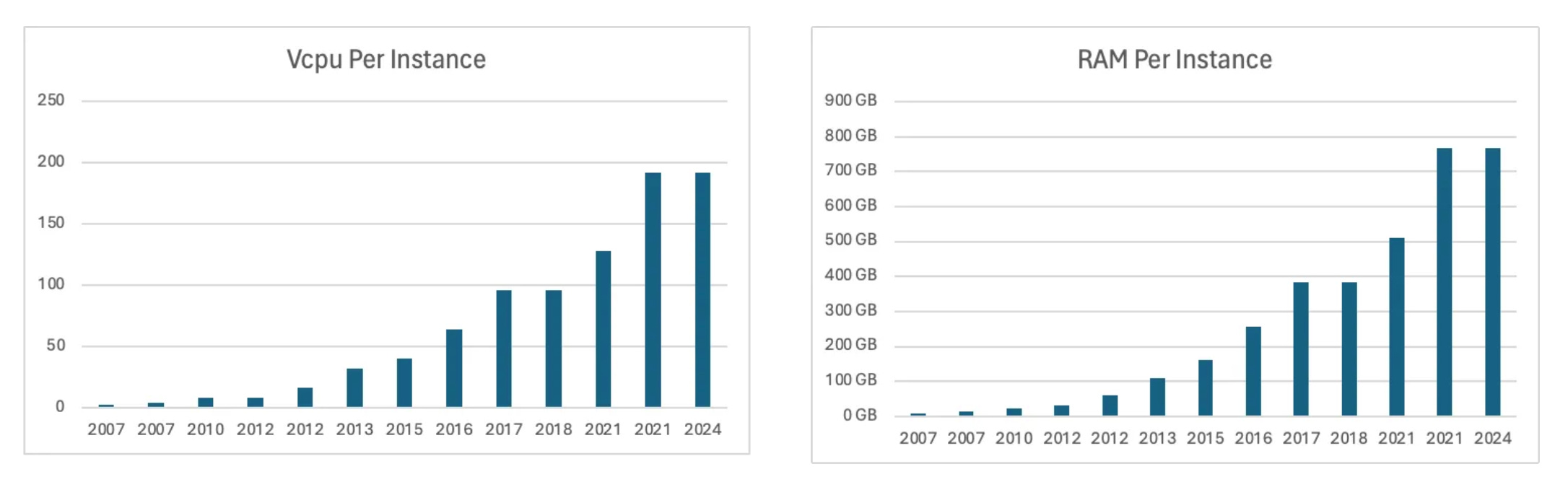
In 2006, when Hadoop MapReduce emerged, the first AWS EC2 instances (m1.small) had just 1 CPU and less than 2 GB RAM. Today's cloud providers offer instances with 64+ cores and 256GB+ of RAM, fundamentally changing the equation for what's possible with single-node processing.
Examining the evolution of balanced EC2 instances in terms of memory and CPU (with a 1:4 ratio) over the years reveals exponential growth, as these instances have become increasingly powerful over time.
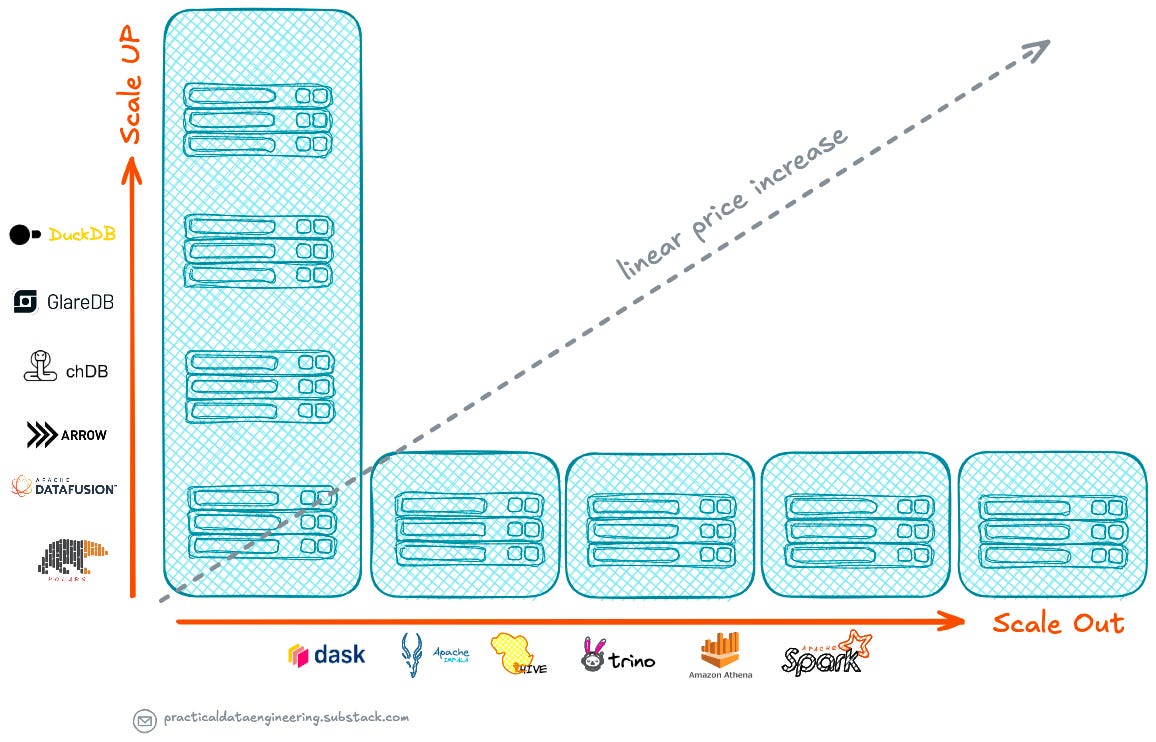
The Economics of Scale-Up vs. Scale-Out
One might assume that scaling out across multiple smaller instances is more cost-effective than using larger instances. However, cloud pricing models tell a different story.
The cost per compute unit on cloud is consistent whether you use a smaller instance or larger one as the cost increases linearly.
That is the cost of larger cloud compute instances increases linearly and the overall price remains the same regardless of whether you use one larger instance or multiple smaller instances, as long as the total number of cores and memory is the same.
Using AWS's m5 instance family as an example, regardless of whether you scale up with a single m5.16xlarge instance or scale out with eight m5.2xlarge instances, the price per hour will remain the same.

This hardware evolution has important implications for system architecture decisions as:
Modern instances can handle workloads that previously required dozens of smaller nodes, and they do so with reduced complexity and overhead.
This raises a critical question:
From a cost-performance perspective, if a single-node query engine can handle the majority of workloads efficiently, is there still a benefit to distributing processing across multiple nodes?
The Performance Case for Single-Node Processing
Modern single-node processing engines leverage advanced techniques to deliver impressive performance.
Engines like DuckDB and Apache DataFusion achieve superior performance through sophisticated optimization techniques, including vectorized execution, parallel processing, and efficient memory management
Numerous benchmarks illustrate these performance improvements:
Vantage reported that when they switched from Postgres to DuckDB for cloud cost analysis, they saw performance improvements between 4X and 200X.
Fivetran's CEO benchmarks using TPC-DS datasets showed DuckDB outperforming commercial data warehouses for datasets under 300 GB.
An experiment with 1 billion row fake order data, comparing DuckDB with Amazon Athena.
Why Choose Single-Node Processing?
The case for single-node processing extends beyond just performance. For the majority of businesses, modern single-node engines offer several compelling advantages:
They dramatically simplify system architecture by eliminating the complexity of distributed systems. This simplification reduces operational overhead, makes debugging easier, and lowers the barrier to entry for teams working with data.
They often provide better resource utilisation. Without the overhead of network communication and distributed coordination, more computing power can be dedicated to actual data processing. This efficiency translates directly to cost savings and improved performance.
They offer excellent integration with modern data workflows. Engines like chDB and DuckDB can directly query data from cloud storage, work seamlessly with popular programming languages, and fit naturally into existing data pipelines.
The embeddable nature of some of these engines enables seamless integration with existing systems—from PostgreSQL extensions like pg_analytics and pg_duckdb to various modern Business Intelligence tools—expanding analytical capabilities without disrupting established workflows.
Challenges and Limitations
While single-node processing offers many advantages, it's important to acknowledge its limitations.
Some engines still face challenges in fully utilising all available CPU cores on large machines, particularly as core counts continue to increase. Memory hierarchy bandwidth between RAM and CPU can become a bottleneck for certain workloads.
When reading from cloud storage like S3, single-connection transfer speeds may be limited, though this can often be mitigated through parallel connections and intelligent caching strategies. And naturally, there remain workloads involving very large datasets that exceed available memory and storage, requiring distributed processing.
Conclusion
The rise of single-node processing engines represents a pragmatic shift in data analytics. As hardware capabilities continue to advance and single-node engines become more sophisticated, the need for distributed processing will likely continue to decrease for most organisations.
For the vast majority of companies, single-node processing frameworks offer a more efficient, cost-effective, and manageable solution to their data analytics needs. As we move forward, the key is not to automatically reach for distributed solutions, but to carefully evaluate actual workload requirements and choose the right tool for the job.
The future of data processing may well be less about managing clusters and more about leveraging the impressive capabilities of modern single-node systems.
Thanks, I’ve seen 500 row Store dimension tables split into 100 parquet files. Sometimes smaller is better.